

2019年12月のAWSのリリースでLambdaからRDSを使う際の問題点であったコールドスタートとコネクション数の問題は解決されました。
この問題点の詳細はAWSのSAである西谷さんのなぜAWS LambdaとRDBMSの相性が悪いかを簡単に説明する の記事で述べられてますので興味ある方は読んでみてください。
これまでは多くのケースにおいてDynamoDBをサーバーレスアーキテクチャのデータベースとして検討することがファーストチョイスとなっていましたが、今はユースケースに応じてどちらでも選択することが出来ます。
このタイミングで改めてサーバーレスアーキテクチャにおけるデータベース選定をどのように行えばよいのか考えてみましょう。
データベースとしての構造上の違い
まずはRDSとDynamoDBの使い分けを考えるにあたってそれぞれのデータベースとしての構造上に違いを整理しましょう
RDSの特徴
常に一貫性を保証する仕組みであること
DynamoDBと比較したときの一番大きな特徴は、RDSはリレーショナルデータベース(RDB)であることでしょう。

RDBはデータを列と行で成り立つ2次元な表形式である「テーブル」で表現し、クライアントからは強力なクエリ言語であるSQLを通してデータにアクセスします。このSQLによる操作とトランザクションの機構により、どのクライアントから見ても操作するデータが必ず同じ状態であることを保証します(一貫性)。そして、CommitやRollbackの操作を通してトランザクションが途中で失敗して中途半端な状態にならず、完全に失敗するか成功するかのどちらかであることを保証します(原子性)。
これらの特性を通して常にデータに整合性が取れていることを保証し、データベースとしての信頼性を担保します。
RDSのスケールの限界
しかし、大量にアクセスのある環境下においては、この特性がボトルネックになってしまいます。
読み取り性能のパフォーマンスと耐久性を向上させるためにリードレプリカでスケールアウトさせる構成を取ることが一般的でしょう。また、書き込み含めた性能を担保するためにデータを複数のノードに分けて分散配置することで、データベースへのリクエストを分散させてスループットを向上させるシャーディングといった手法を取られることもあります。
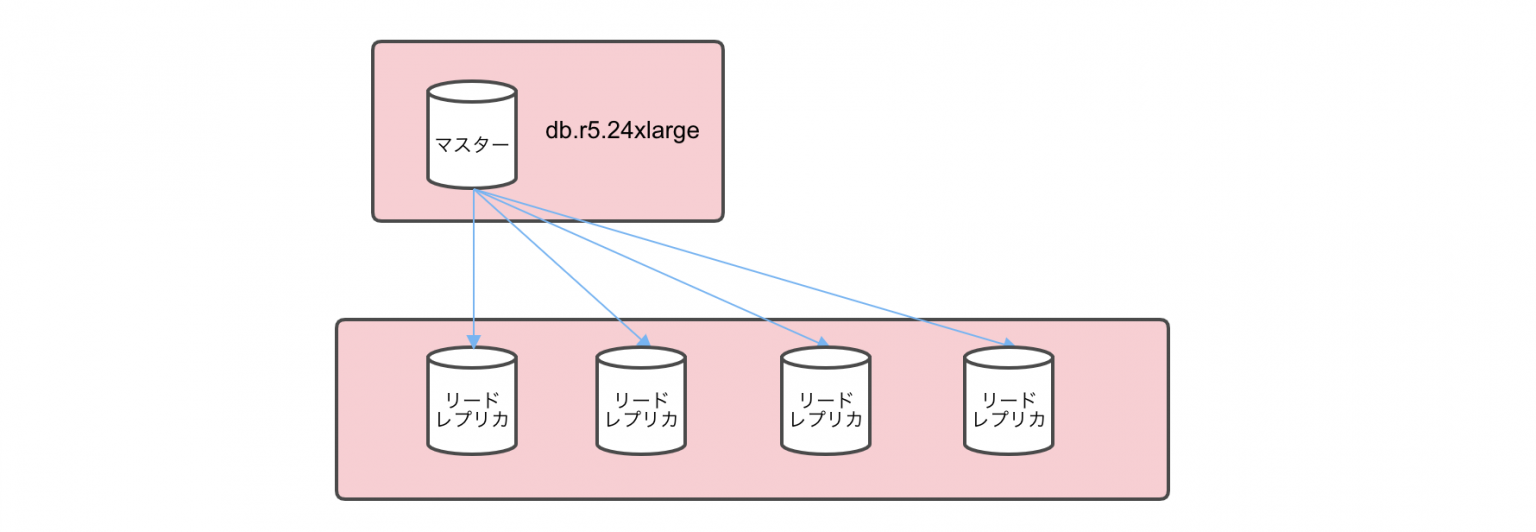
しかし、データベースのノードが分散された状態で一貫性を確保するためには、ノード間で常にデータの同期を取る必要が出てくるため、その仕組は非常に複雑で困難なものになってきます。
つまり、RDBの仕組みを使い一貫性を保証するためには共有のストレージである必要があり、分散ストレージを使って水平方向にスケールすることは限界があるのです。
RDSはその高い一貫性を実現するための仕組みと引き換えにスケーラビリティには天井が存在すると考えていいでしょう。
DynamoDBの特徴
データの分散配置による可用性と拡張性の確保
DynamoDBは、多くのトラフィックを捌くことが出来るように、データをパーティションに分散配置し、それによってスループットを向上させる仕組みとなっています。
データは、そのパーティションキーに対してハッシュ関数を実行することで配置先のパーティションが決定されます。そして、パーティションあたりの性能は予め決まっていため、スケールさせるためにはデータが均一に各パーティションに分散できるようにキー設計を行う必要があります。
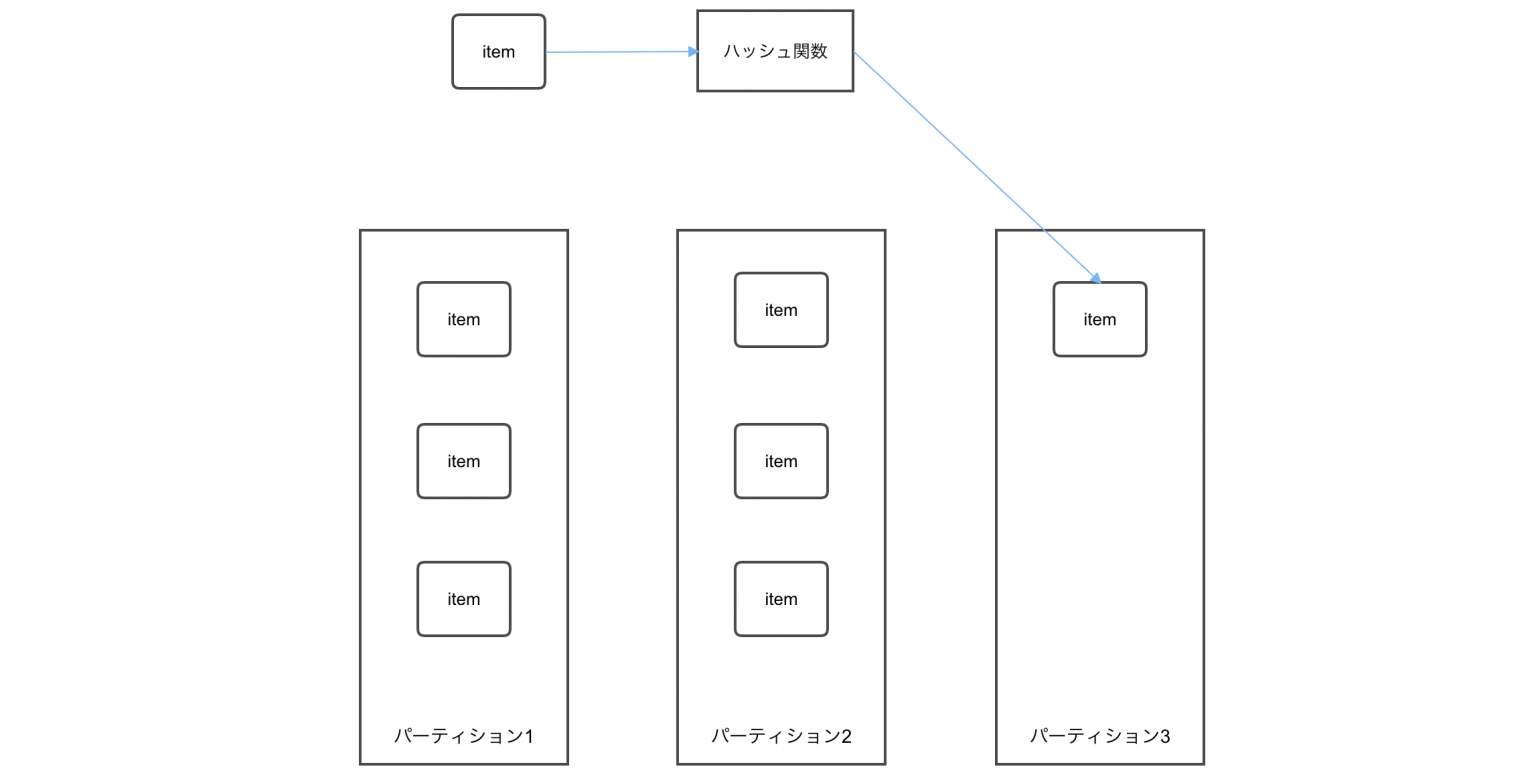
さらにデータが増えてもパーティションはAWSが自動で追加してくれて、オンデマンドで再配置してくれます。つまり、自動かつAWSの制約の範囲内で無限にスケールアウトしてくれる仕組みになっています。
結果整合性モデルの採用
データの操作に関しては結果整合性モデルが基本となっており、常に一貫性を保証するわけではありません(強い整合性を選べるオプションもある)。そして、最終的には非同期でデータセンター間でコピーされて一貫性のある状態になります(Eventual Consistancy)。
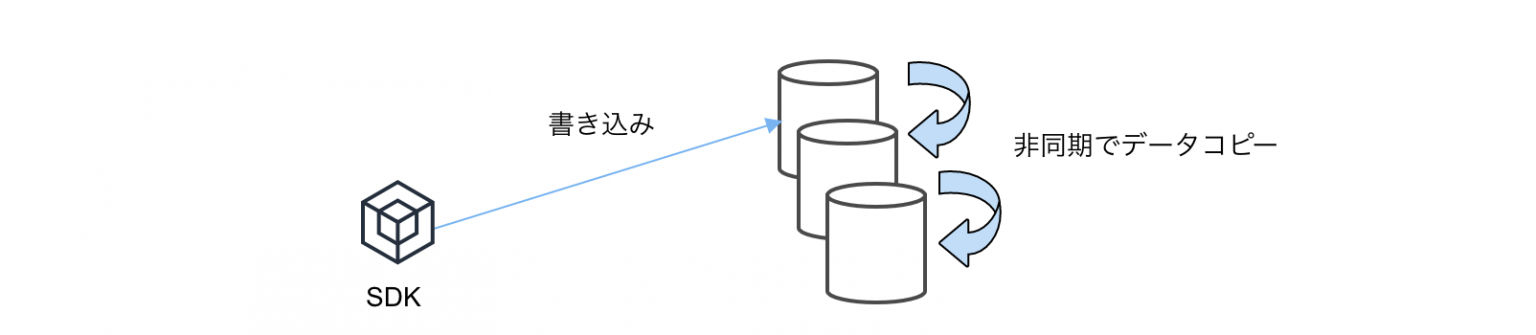
このように一貫性を弱めることで、データが分散ストレージに配置出来るようになり、結果としてスケールアウトすることを容易にしています。
DynamoDBは性能を重視するために強い一貫性を捨てているというわけですね。ここはRDSのデータベースとしての特性を考えた時の大きな違いとなります。
つまり
ざっくり構造上は以下のような違いがあり、作るアプリケーションの特性に合わせてデータベースを選定するのは1つの良いやり方です。
- RDSは強い一貫性を保つためにそのスケール性能には限界がある
- DynamoDBは一貫性を弱めることでスケール性能は理論上無限大である
例えば、IoTで大量トラフィックのデータを捌く場合には一貫性を捨ててでも性能を重視したいケースがほとんどでしょうし、口座間取引のように確実にデータに不整合が発生しては行けない場合は一貫性を重視すべきでしょう。
しかし、選定理由にはこれ以外のファクターもあります。後編の記事ではさらに現実的な側面から使い分けについて述べてみます。