Amazon AthenaからAmazon S3にデータを読み込ませる設定
Amazon S3の設定
Amazon AthenaとはS3においたデータに対してSQLを発行して直接データを操作できるサービスです。S3上にCSVファイルなどをおいて、そのデータに直接SQLでクエリをかけることができます。いわゆるサーバーレスなサービスであり、インフラやデータベースの構築などは不要です。従量課金制であり、クエリの数やデータの量が少ない場合は、Amazon Redshiftよりも格安で使用が可能です。
まずはS3上に「tableau-test-bucket-horike」というバケットを作成しましょう。
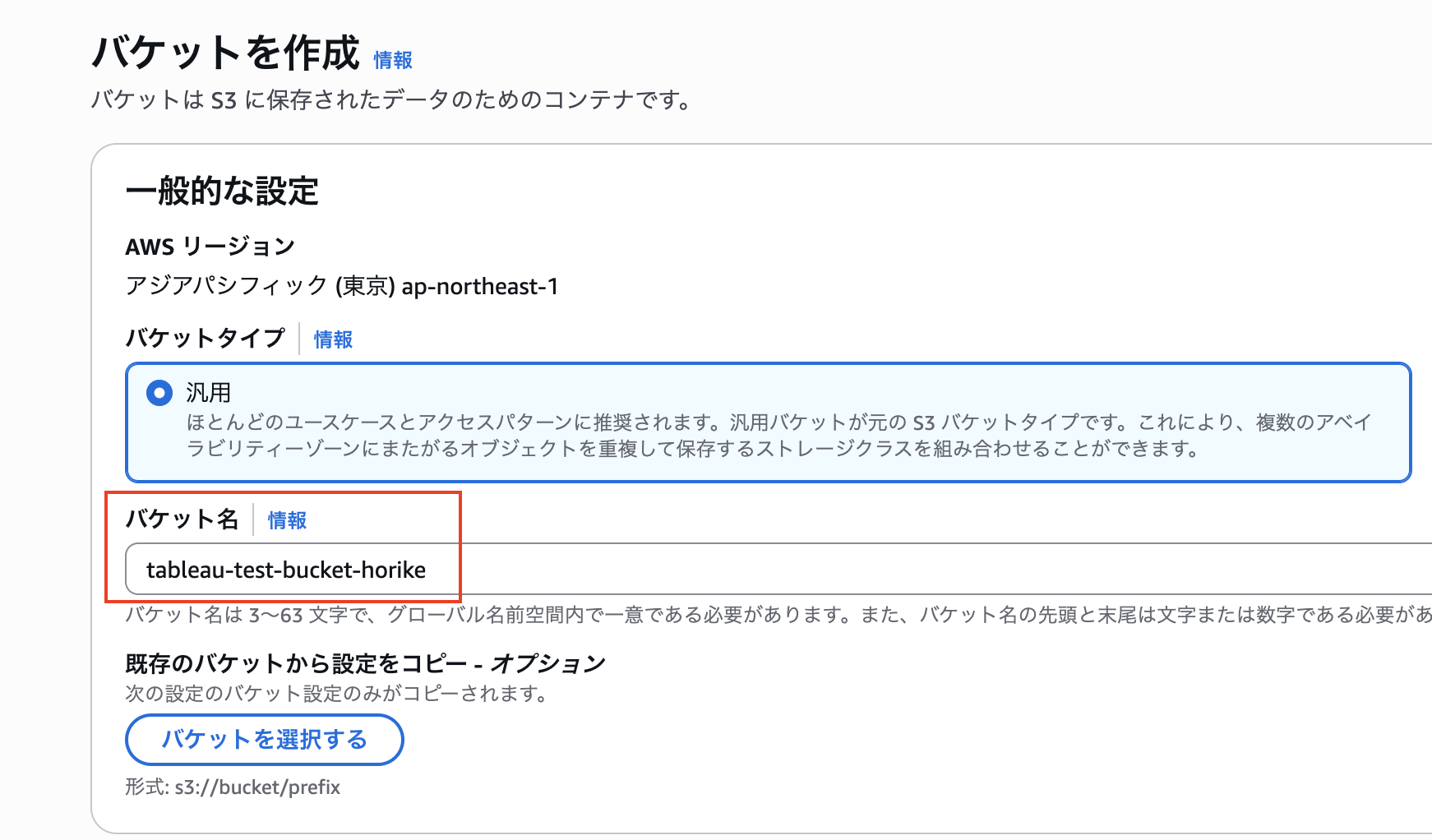
その配下に「data/sample_data.csv」というファイルを配置しますファイルは以下のようにダミーのCSVデータが入っています。
id | name | age | city | created_at |
|---|---|---|---|---|
1 | Alice | 30 | Tokyo | 2024-01-01 |
2 | Bob | 28 | Osaka | 2024-02-15 |
3 | Charlie | 35 | Nagoya | 2024-03-10 |
4 | David | 42 | Sapporo | 2024-04-05 |
5 | Eve | 25 | Fukuoka | 2024-05-20 |
S3バケットにAthenaからアクセスが可能なように以下のようなバケットポリシーを「tableau-test-bucket-horike」に対して設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowAthenaToPutObjects",
"Effect": "Allow",
"Principal": {
"Service": "athena.amazonaws.com"
},
"Action": [
"s3:PutObject"
],
"Resource": "arn:aws:s3:::tableau-test-bucket-horike/*",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "<YOUR-AWS-ACCOUNT-ID>"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:athena:*:<YOUR-AWS-ACCOUNT-ID>:workgroup/*"
}
}
},
{
"Sid": "AllowListBucket",
"Effect": "Allow",
"Principal": {
"Service": "athena.amazonaws.com"
},
"Action": "s3:ListBucket",
"Resource": "arn:aws:s3:::tableau-test-bucket-horike",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "<YOUR-AWS-ACCOUNT-ID>"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:athena:*:<YOUR-AWS-ACCOUNT-ID>:workgroup/*"
}
}
}
]
}これでS3での準備は完了です。
Amazon Athenaの設定
ワーキンググループの設定
Amazon Athena の「ワークグループ(Workgroup)」とは、Athena の クエリ実行をグループ単位で管理・制御するための仕組み です。クエリの出力先、コスト、アクセス制御などを Workgroup 単位で制御できます。特に問題なければデフォルトで用意されているprimaryというワークグループを使用しましょう。
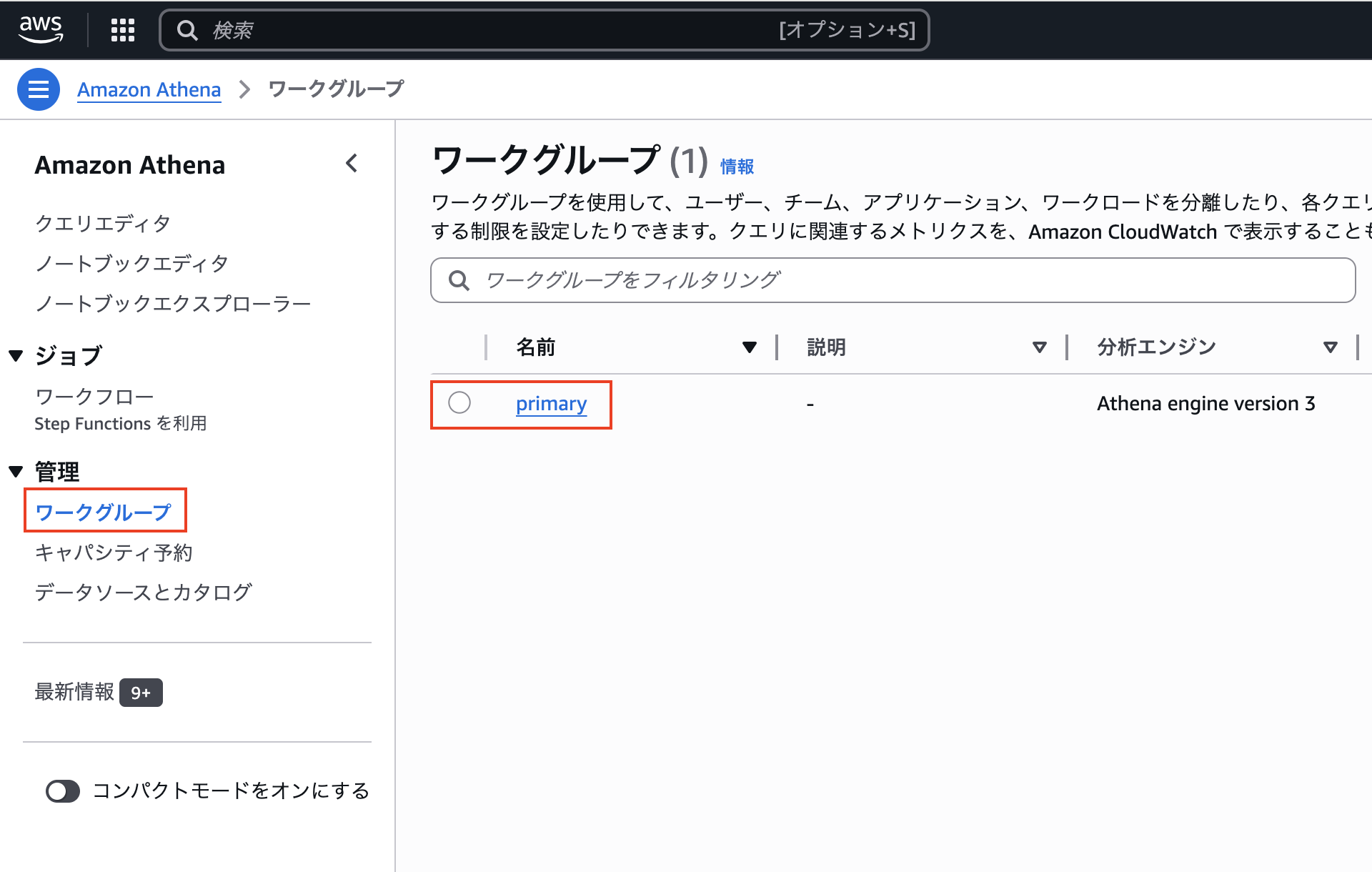
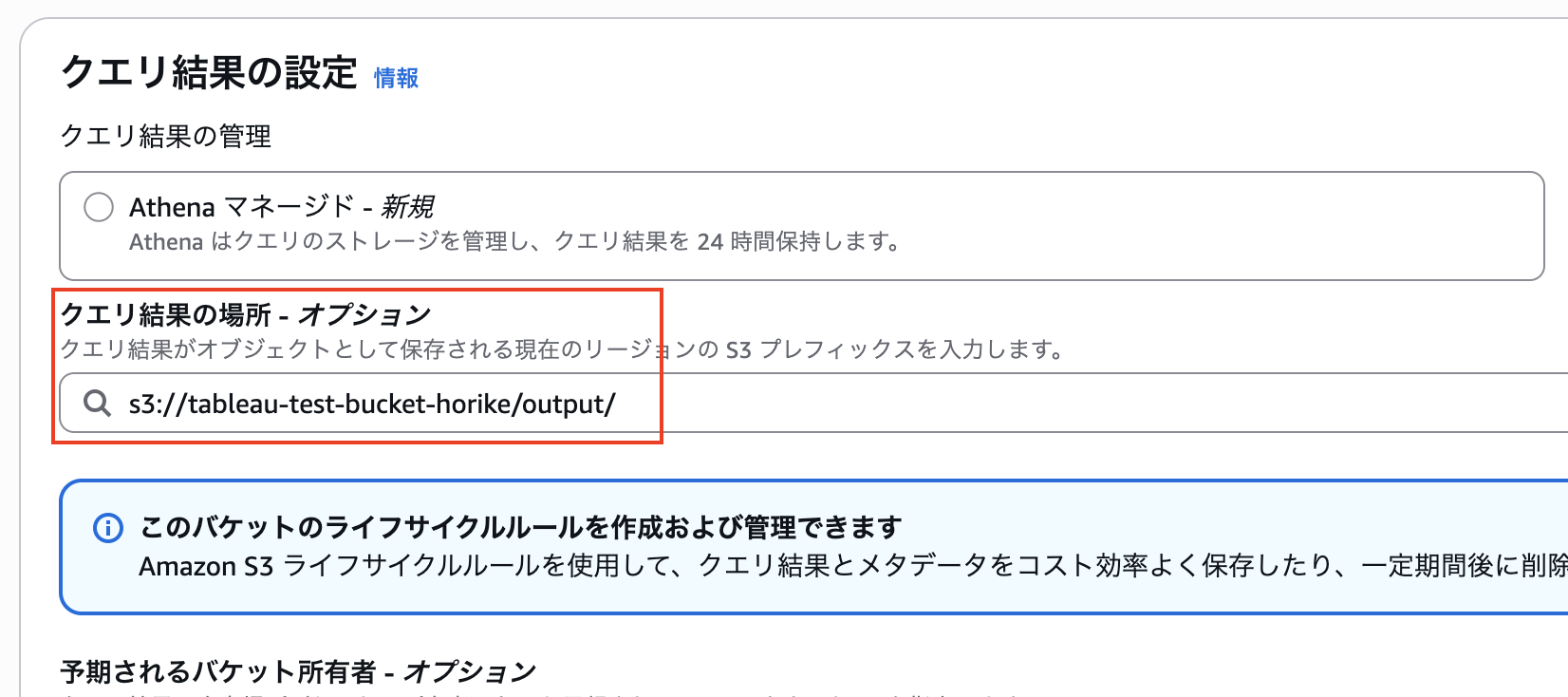
そして、そのワーキンググループを編集してクエリ結果が保存されるバケットとパスを設定します。
テーブルの作成
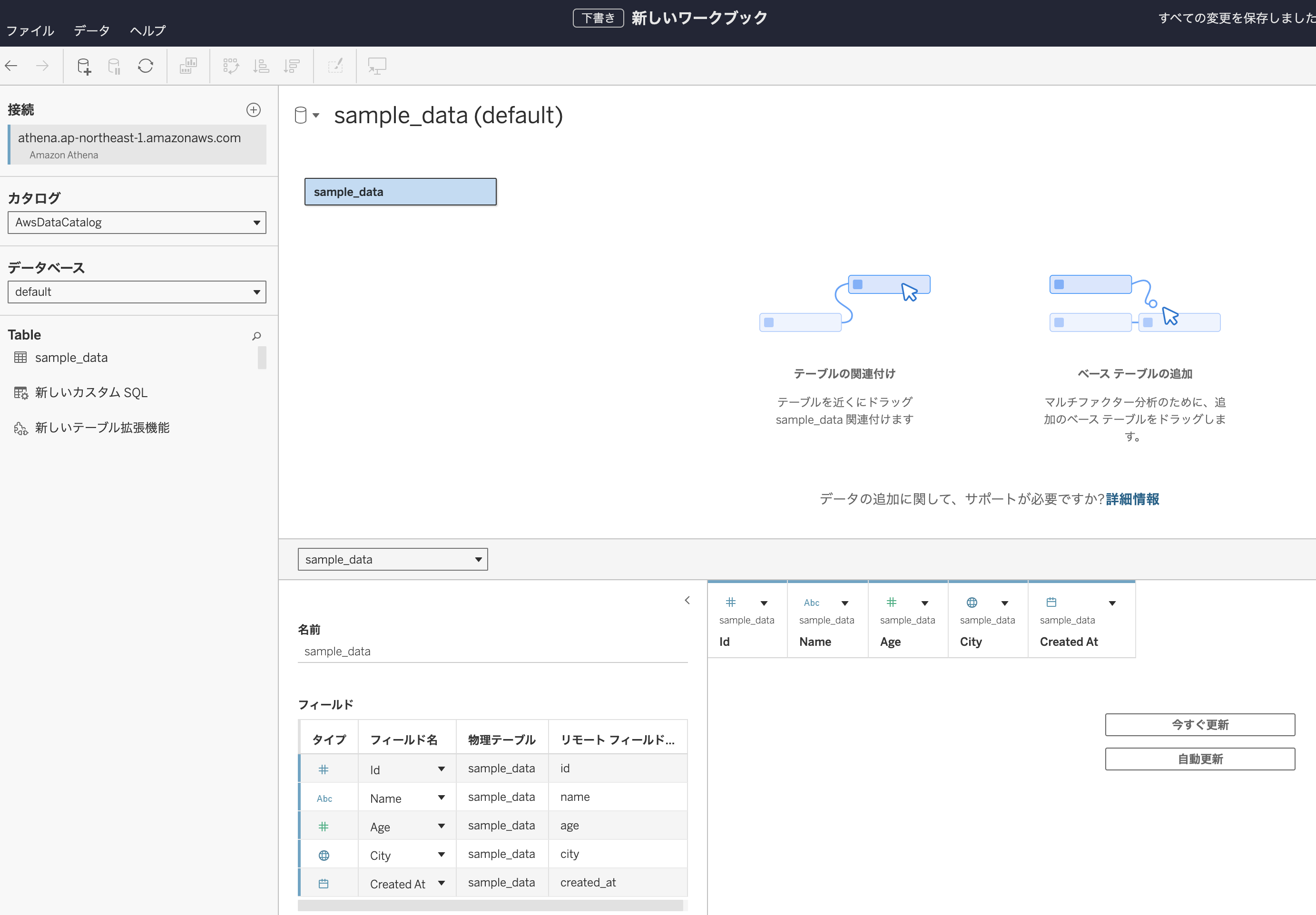
AthenaからS3上のデータが読めるようにAthena上でテーブルを設定します。Athenaのマネジメントコンソールのトップ画面に戻りクエリエディタを起動して下さい。

テーブルとビューから作成を選び「S3バケットデータ」を選択します。
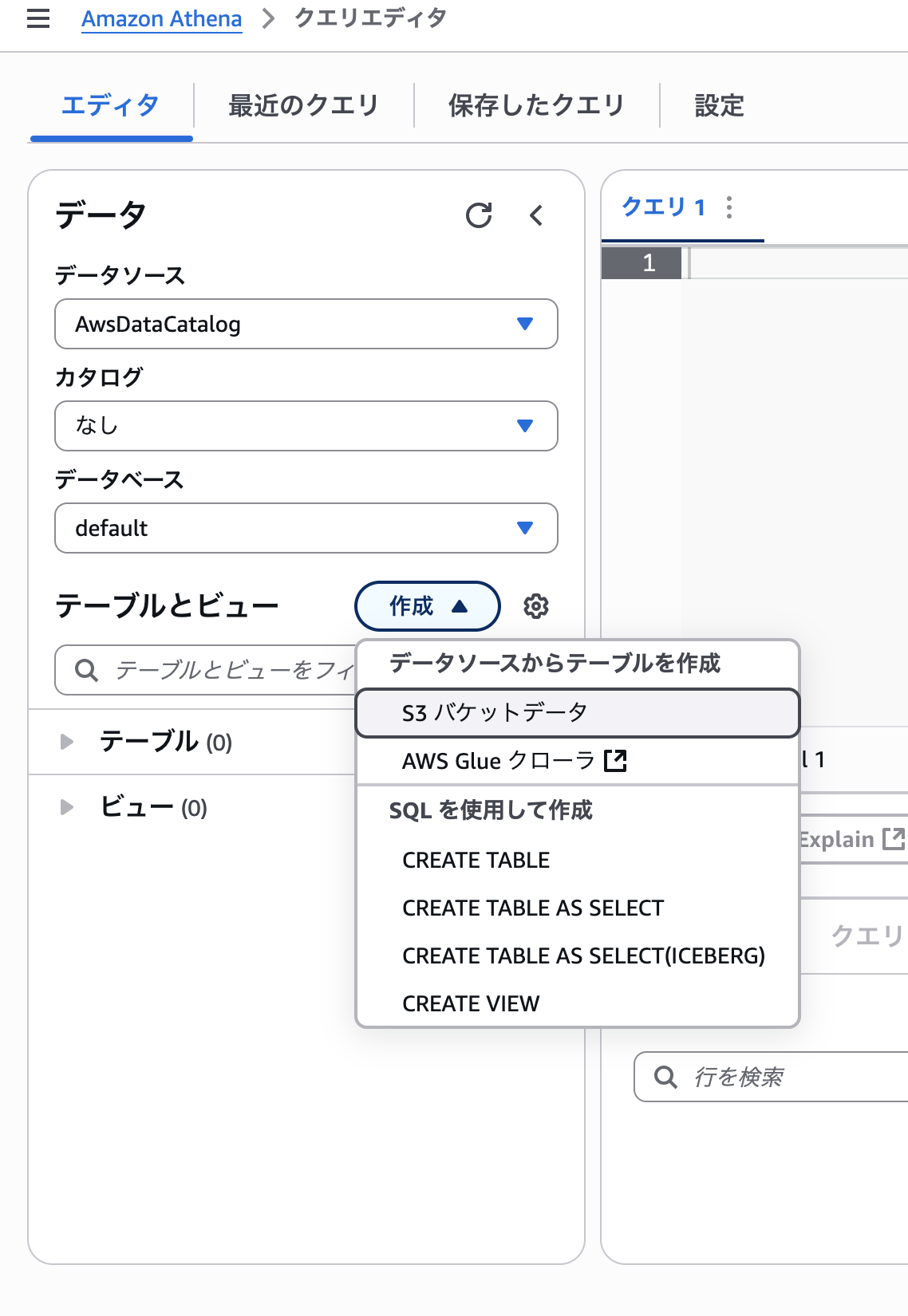
テーブル名には好きなテーブル名を指定して下さい。データセットに関しては先程入力用のCSVを配置したバケットのプレフィックスを指定します。
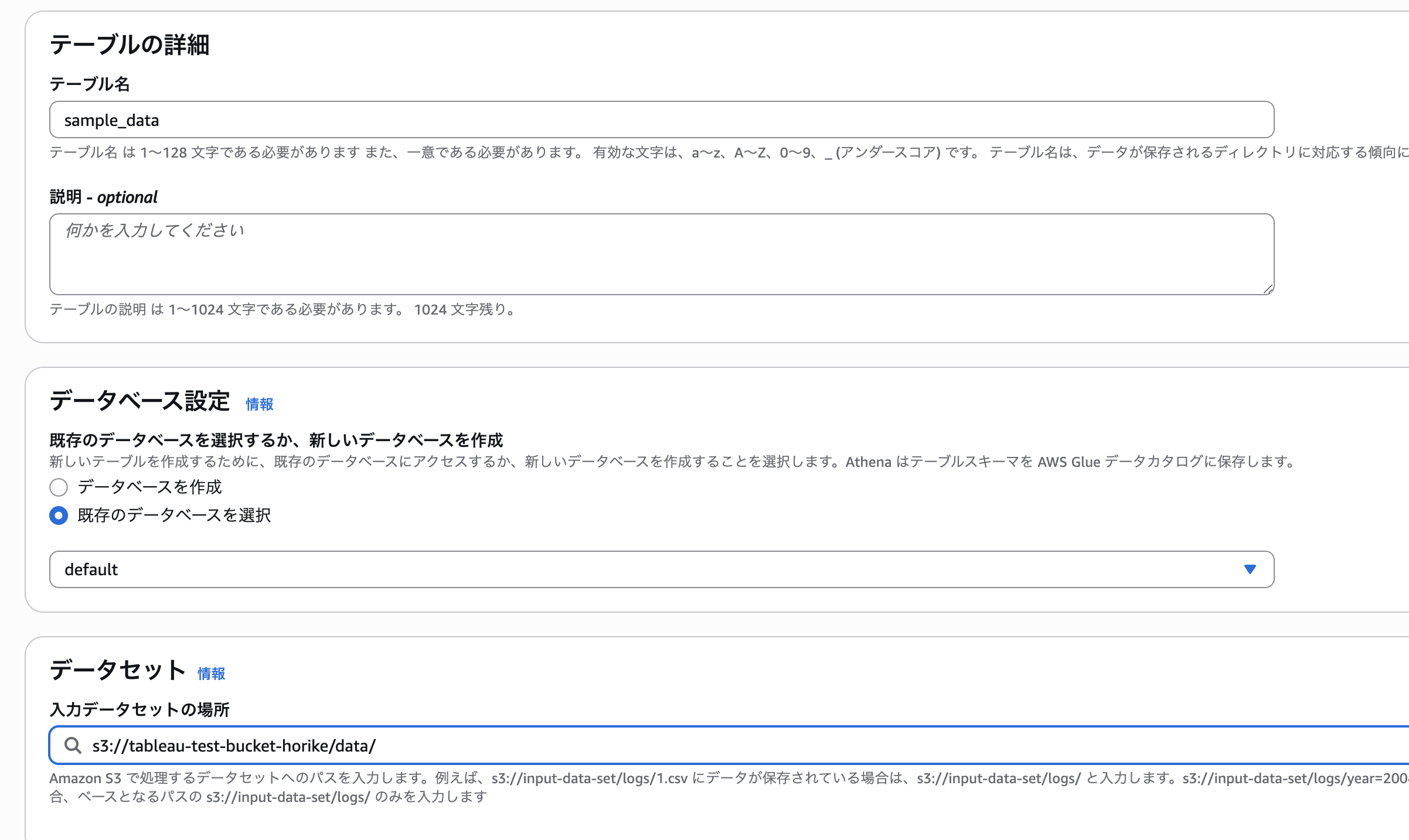
今回は、CSVが元データとなっているため、ファイル形式にはCSVを指定します。
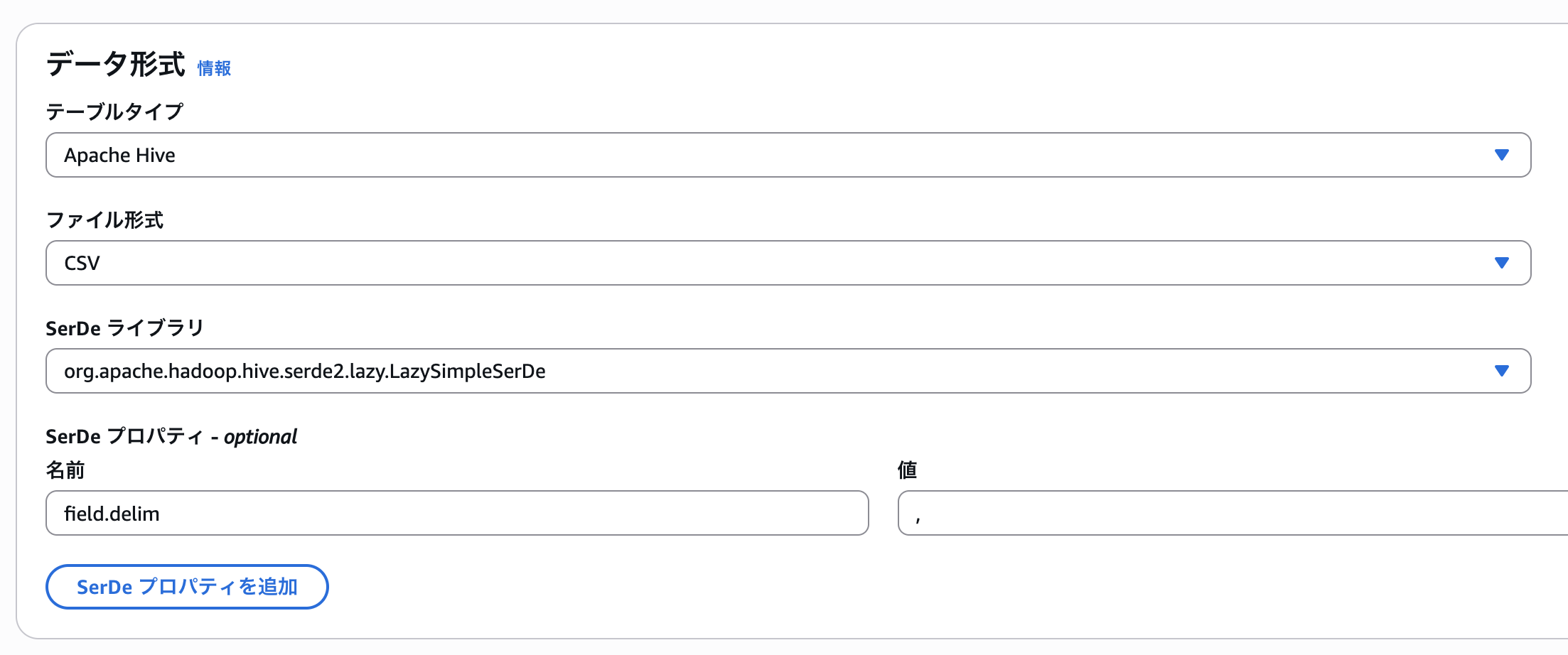
テーブルの列の設定を行います。CSVのデータ形式に合わせて以下のように設定を行います。

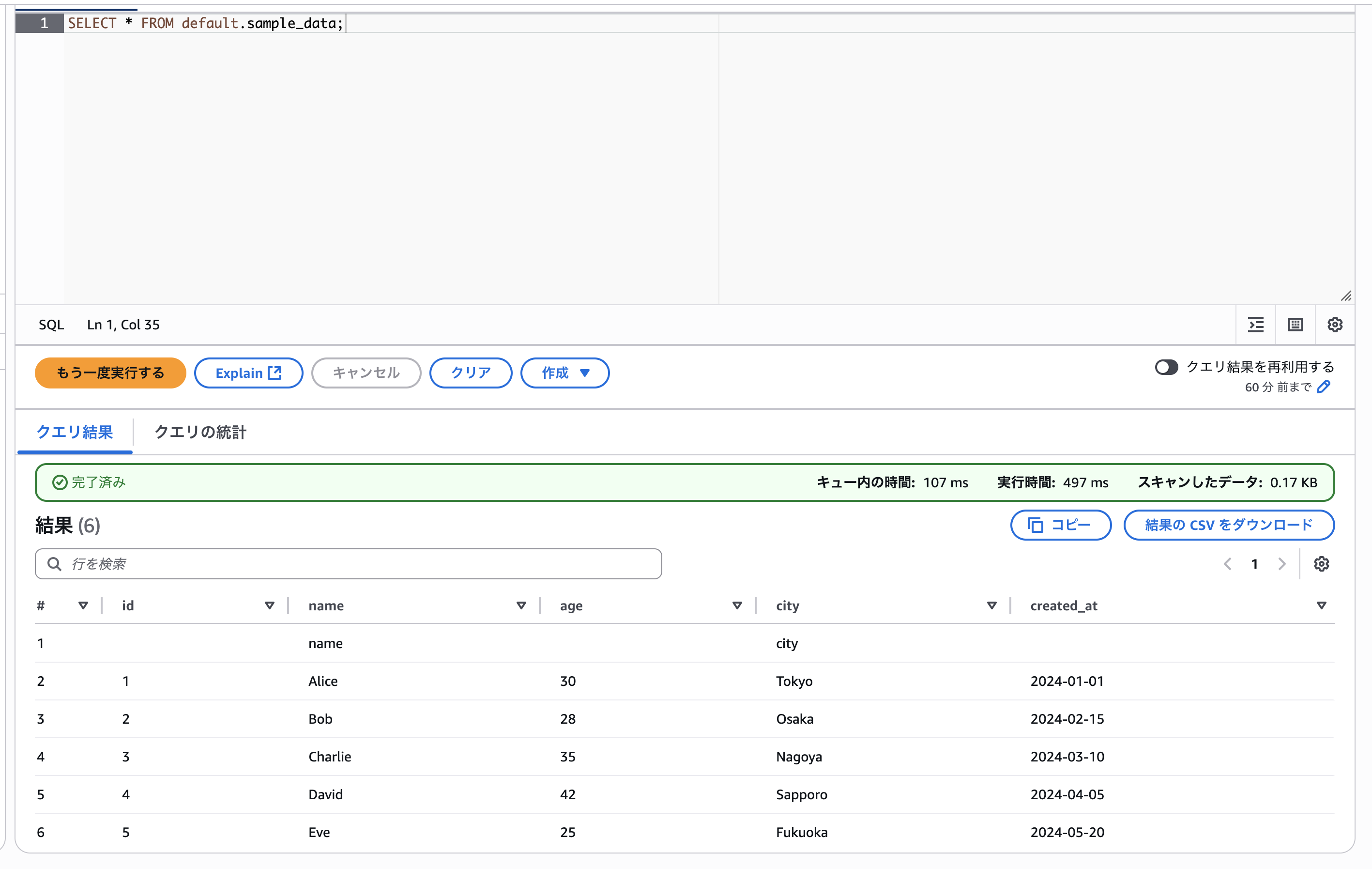
正しくテーブルが設定できているか実際に試してみましょう。SELECT文でCSVのデータを全件取得するSQLを発行しましたが以下のように正しくデータが取得できていることが確認できます。
IAMユーザ
TableauからAthenaに接続するためのIAMユーザを作成して、アクセスキーとシークレットキーを作成します。TableauからAthenaに接続するにはIAMユーザかOAuthを使う方法がありますが、今回は作業簡略化のためIAMユーザを作成します。実務ではOAuthをつかったほうがよりセキュアでしょう。
ポリシーとしては以下の権限を付与します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AthenaFullAccess",
"Effect": "Allow",
"Action": [
"athena:*",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetTable",
"glue:GetTables",
"glue:GetPartition",
"glue:GetPartitions",
"glue:GetUserDefinedFunctions"
],
"Resource": "*"
},
{
"Sid": "S3AccessForAthenaQueryResults",
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::tableau-test-bucket-horike",
"arn:aws:s3:::tableau-test-bucket-horike/*"
]
}
]
}Tableauの設定
新しいワークブックを開くとデータ接続のコネクタとしてAmazon Athenaが選択できるようになっていますので、ここを選択して接続の設定を行います。
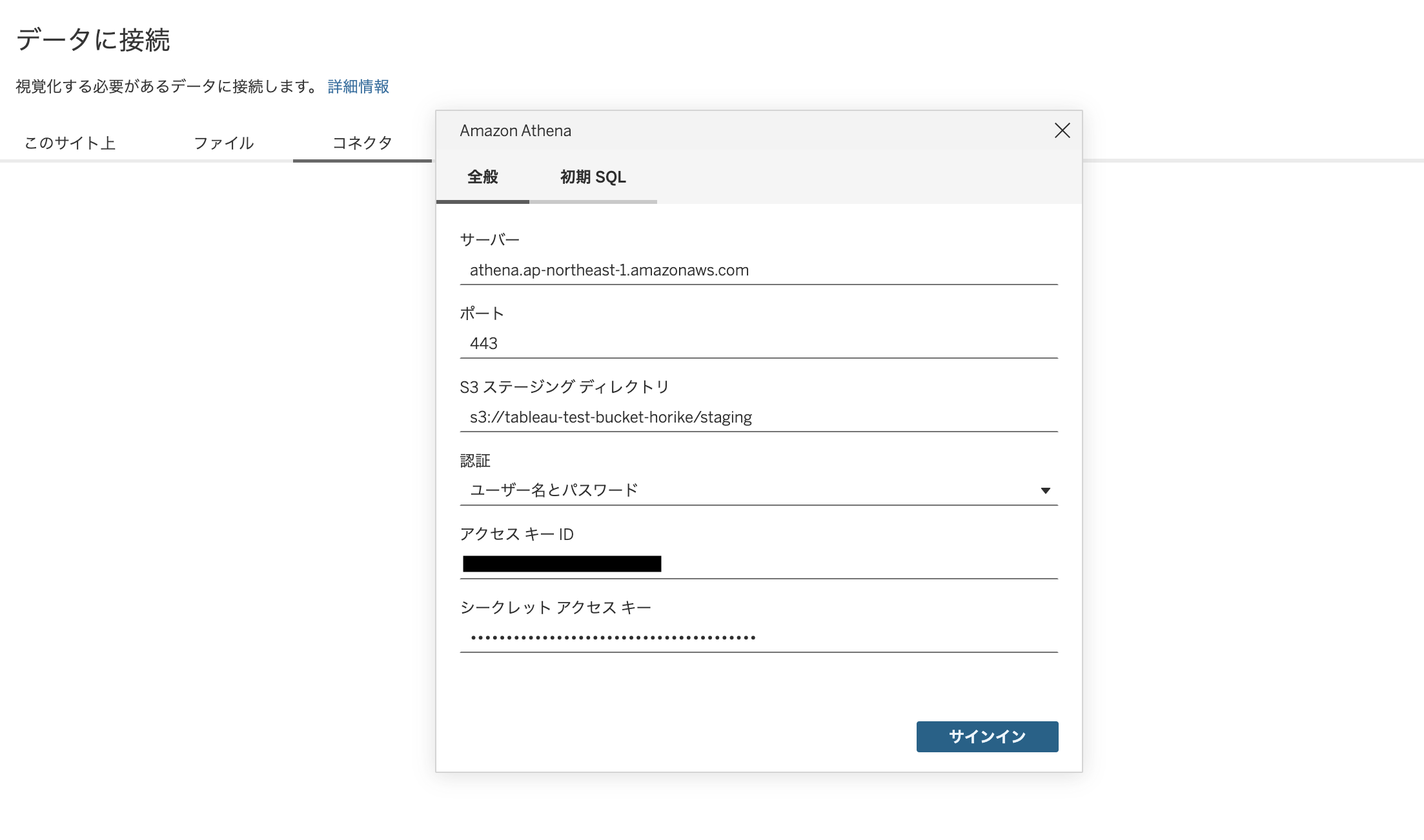
以下画面よりAthenaのコネクション情報を設定します
- サーバー:athena.ap-northeast-1.amazonaws.com(任意のリージョンを指定して下さい)
- ポート:443
- S3ステージングディレクトリ:s3://tableau-test-bucket-horike/staging(任意のバケット名とパスを設定して構いません。Athenaのクエリ結果を一時的に保存するバケットですが、AWS側で設定した「クエリ結果の場所」とは違っても構いません)
- アクセスキー:AWSのアクセスキー
- シークレットキー:AWSのシークレットキー
サインインをクリックすると正しくAthenaと連携してデータをTableauにインポートできることが確認できました。