

DynamoDBのテーブル設計の基礎
DynamoDBのテーブル設計は以下のようなポイントに基づいて行います。
- アクセスパターンをベースにしてデータモデリングを行う必要がある。RDSのように正規化を行うという手順は踏まない
- 各パーティションにデータが分散するキー設計。ホットパーティションを発生させない
- 基本的に複数データの読み込みや検索はGSIで表現する。GSIで対応しきれないケースは別テーブルに専用のデータを作るのもあり
スキーマレスDBであるDynamoDBの特性を考えると、正規化を行なってテーブルを設計する必要性はありません。アクセスパターンに基づいてデータモデリングを行なうことが重要になります。具体的な手順としては以下のとおりです。
- 必要なデータのエンティティとリレーションシップをまとめる
- データのアクセスパターンをまとめる
- テーブル設計
それではここから具体的なブログシステムを用いてテーブル設計を行いましょう。
ブログシステムの仕様
以下を仕様とします。最近のブログサービスなどではコメントの機能はあまり見ませんが、あった方がテーブル設計のイメージが付きやすいかと思うので入れています。
- ユーザ登録してブログ記事が投稿できる
- 投稿したブログにはコメントが可能
- 記事は最新投稿順に一覧で見ることが出来る
- ユーザごとの記事も一覧で見ることが出来る
- 記事に紐付いたコメントは時系列順に並んで表示される
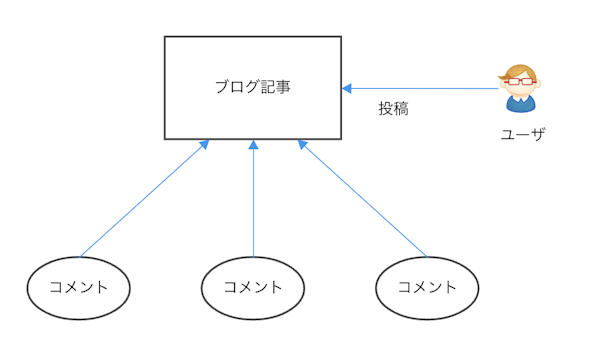
データのエンティティとリレーションシップをまとめる
まずは以下のようにまとめてER図に落とし込みましょう
- エンティティとしては、「記事」「コメント」「ユーザ」の3種類があります
- ユーザと記事は1対多の関係。記事とコメントは1対多の関係があります
データのアクセスパターンをまとめる
どのようなCRUD操作やソート処理が行われるのかをすべて洗い出しましょう。今回のブログシステムの場合だと以下のようになります。
- ユーザを登録する
- ユーザIDを指定してユーザの取得と更新と削除を行う
- 投稿データの登録をする
- 投稿IDを指定して投稿データの更新と削除を行う
- 特定投稿データに対してコメントを登録する
- コメントIDを指定してコメントの更新と削除を行う
- 投稿IDを指定して特定の投稿データを取得する
- 投稿データの一覧を取得して、公開日の降順でソート
- 投稿者ごとの投稿データの一覧を取得して、公開日の降順でソート
- 投稿IDを指定して特定の投稿データに紐づくコメントの一覧を取得してコメント投稿日付の降順でソート
テーブル設計
- 基本方針
- 今回はベストプラクティスに沿って1テーブルで表現
- PK(パーティションキー)を
<エンティティ名>#<ID>の形式で表現して、エンティティ毎の主キーとする - SK(ソートキー)に各データの項目名を定義
- Valueに各項目ごとの値を入れる
- CRUDの設計方針
- IDを指定しての登録更新削除を行えるようにする
- 記事の一覧やコメントの一覧の取得用にGSI(グローバルセカンダリインデックス)を生成する
- 記事のソート
- 記事を最新順及びユーザごとの最新順に並べ替えたりフィルタをするためにDynamoDBでは前方一致による絞り込みを多用します。具体的は
begins_withクエリを使用します。<Key>_<値>#<Key>_<値>のように区切り文字を使用してデータを表現し前方一致でデータを絞り込みますauthor_1111-1111-1111#publishDt_20210403を前方一致で検索して、以下のようなクエリでユーザIDが1111-1111-1111の記事一覧を公開日の降順で取得できます{ SK = 'POST#sortPublishDtByAuthor' Value = begins_with('author_1111-1111-1111#') }
- 記事を最新順及びユーザごとの最新順に並べ替えたりフィルタをするためにDynamoDBでは前方一致による絞り込みを多用します。具体的は
これらの方針に従ってテーブルを設計すると以下のようになります。
PK | SK(GSI-PK) | Value(GSI-SK) |
|---|---|---|
POST#aaaa-aaaa-aaaa | POST#aaaa-aaaa-aaaa | |
POST#aaaa-aaaa-aaaa | POST#title | タイトルA |
POST#aaaa-aaaa-aaaa | POST#content | 本文A |
POST#aaaa-aaaa-aaaa | POST#sortPublishDt | publishDt_20210403 |
POST#aaaa-aaaa-aaaa | POST#sortPublishDtByAuthor | author_1111-1111-1111#publishDt_20210403 |
POST#bbbb-bbbb-bbbb | POST#bbbb-bbbb-bbbb | |
POST#bbbb-bbbb-bbbb | POST#title | タイトルB |
POST#bbbb-bbbb-bbbb | POST#content | 本文B |
POST#bbbb-bbbb-bbbb | POST#sortPublishDt | publishDt_20210405 |
POST#bbbb-bbbb-bbbb | POST#sortPublishDtByAuthor | author_1111-1111-1111#publishDt_20210405 |
POST#cccc-cccc-cccc | POST#cccc-cccc-cccc | |
POST#cccc-cccc-cccc | POST#title | タイトルC |
POST#cccc-cccc-cccc | POST#content | 本文C |
POST#cccc-cccc-cccc | POST#sortPublishDt | publishDt_20210407 |
POST#cccc-cccc-cccc | POST#sortPublishDtByAuthor | author_2222-2222-2222#publishDt_20210407 |
COMMENT#xxxx-xxxx-xxxx | COMMENT#xxxx-xxxx-xxxx | |
COMMENT#xxxx-xxxx-xxxx | COMMENT#content | コメント1 |
COMMENT#xxxx-xxxx-xxxx | COMMENT#sortPublishDt | parentPost_aaaa-aaaa-aaaa#publishDt_20210403 |
COMMENT#yyyy-yyyy-yyyy | COMMENT#yyyy-yyyy-yyyy | |
COMMENT#yyyy-yyyy-yyyy | COMMENT#content | コメント2 |
COMMENT#yyyy-yyyy-yyyy | COMMENT#sortPublishDt | parentPost_cccc-cccc-cccc#publishDt_20210405 |
COMMENT#zzzz-zzzz-zzzz | COMMENT#zzzz-zzzz-zzzz | |
COMMENT#zzzz-zzzz-zzzz | COMMENT#content | コメント3 |
COMMENT#zzzz-zzzz-zzzz | COMMENT#sortPublishDt | parentPost_aaaa-aaaa-aaaa#publishDt_20210407 |
USER#1111-1111-1111 | USER#1111-1111-1111 | |
USER#1111-1111-1111 | USER#lastName | 山田 |
USER#1111-1111-1111 | USER#firstName | 太郎 |
まとめ
以上でDynamoDBの設計をブログシステムを題材に解説しました。このような方針でテーブルを設計することでかなり柔軟にアクセスパターンに対応できていることがわかるかと思います。<エンティティ名>#<ID> をPKにすることでシステムが拡張して新たなエンティティが必要になった際もテーブル構造を変更することなく追加できます。そして区切り文字やbegins_with クエリ及びGSIを使用することでデータのソートやフィルターもDynamoDBでうまく表現できていることがわかります。このあたりのポイントを抑えているとテーブル設計がだいぶやりやすくなるでしょう。弊社ではDynamoDBの設計支援も可能ですので、是非お困りの方はお問い合わせ下さい。