

※ この記事は、以下のように構成されているシリーズの2番目の記事になります。Amazon Bedrock や LangChain に関する基本的な理解、環境のセットアップについては前回の記事(一番目)をご参照ください。
- 今さら聞けない、Amazon Bedrock と LangChain を使った簡単テキスト生成 AI 入門 (Python)
- 今さら聞けない、Amazon Bedrock と LangChain を使った簡単 RAG 入門 (Python)
簡単な Q&A を作ってみて思うこと
前回の記事では、LLM(Large Language Models・大規模なテキスト生成 AI のモデル・GPT や Claude など)に単発の質問を投げて回答をもらう実装をしてみました。この場合、LLM は自分がすでに知っていること(事前に与えられチューニングされたデータセット)に基づいて回答を行います。なので、あまりにもタイムリーで最新の情報について質問したり、そもそもインターネットなどに公開されていないような情報については教えてもらえません。
例えば、以下の例を見てみます。
質問: 2024年の新宿駅の乗降者数の平均を教えてください。
回答: 申し訳ありませんが、2024年の新宿駅の乗降者数の平均を正確にお伝えすることはできません。その理由は以下の通りです:
1. 2024年はまだ始まっていないため、実際のデータは存在しません。
2. 将来の乗降者数を正確に予測することは非常に困難です。様々な要因(経済状況、人口動態、新型コロナウイルスの影響など)が乗降者数に影響を与える可能性があります。
3. 駅の乗降者数は日々変動し、平日と週末、季節によっても大きく異なります。こちらのサンプルでは Claude 3.5 Sonnet を利用していますが、2024年よりも前にチューニングされていることがわかります。よって、2024年の最新情報を聞いても分からないと返されてしまいます。
もちろんこのままの状態でも世の中のあらゆる情報やサンプルコードの生成など、役に立てることは間違いありませんが、みなさんの中でこのような疑問が生まれてくるかもしれません。
「事前に与えられた情報だけでなく、最新または任意の情報を学習させた上で、その内容に沿った形で回答を作ってもらうことは可能なのだろうか?」
このような疑問に応えるのが、これから説明する RAG(Retrieval-Augmented Generation・検索拡張生成)の仕組みです。
RAG (Retrieval-Augmented Generation)・検索拡張生成とは?
昨今よく使われるようになったこの「RAG」という用語ですが、一言で表現すると「外部データを活用した情報検索とテキスト生成」になります。前項の、「事前に任意の情報を学習させた上で回答を作ってもらうことは可能なのだろうか」という疑問に対して、この RAG の仕組みを使って実現することが可能になります。
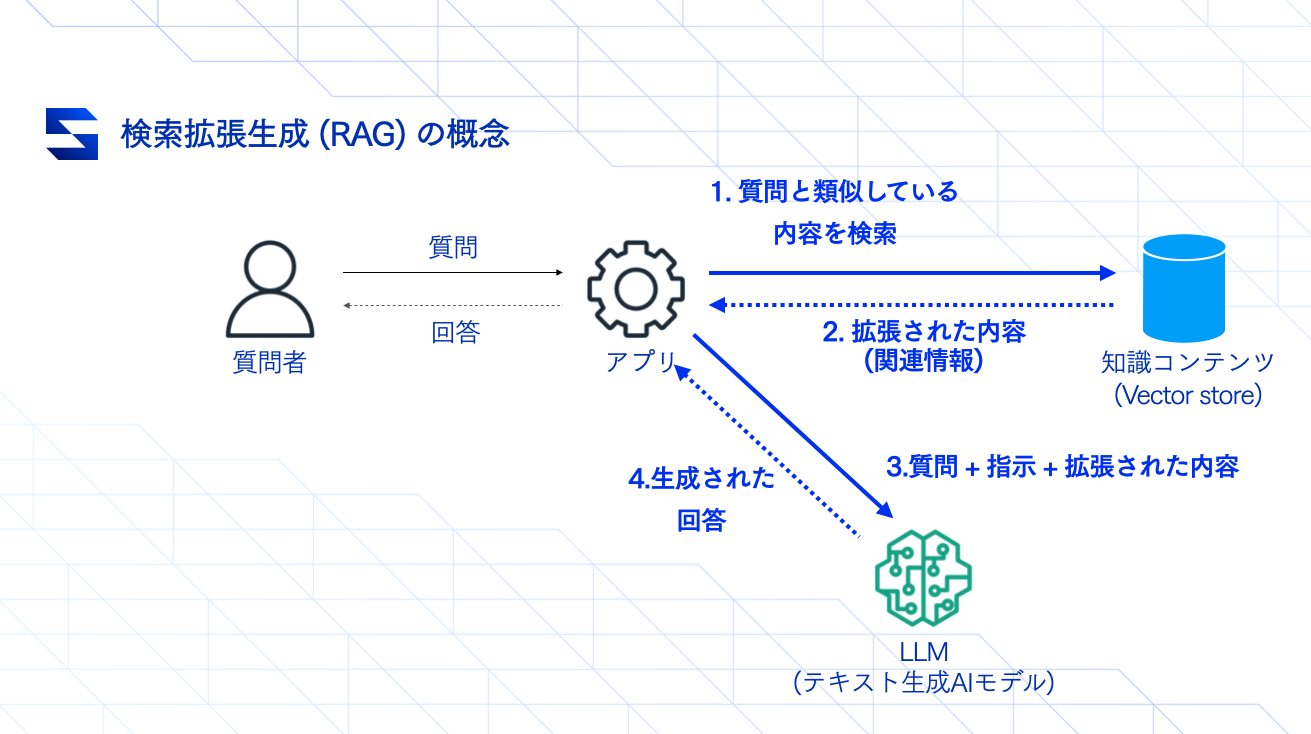
RAG を理解するポイントとしては、「知識コンテンツ(Vector store)」と書かれているパーツの存在になります。LLM が分からない内容や、公開されていない情報を「知識コンテンツ(Vector store)」に保存しておくことで、質問内容に基づく情報の検索が可能になります。
RAG 構成のプログラムは、質問を受けたらまず情報検索を行い、「このような質問を受けました。その質問に関する関連情報はこちらです。では、これらの内容をもとに回答を生成してください」という指示文(=プロンプト)を出すのが、RAG の基本的な流れになります。質問とその関連情報をセットで渡して情報を整理してもらうイメージと考えれば、少しわかりやすいかもしれません。
続いて、「知識コンテンツ(Vector store)」はどのようなもので、どうやって質問のテキストから関連した情報を検索することが可能なのでしょうか?
知識コンテンツ(Vector store / Vector database)の仕組み
RAG の脈略で Vector store または Vector database と言われるこの部分は、一言で言うと「ベクトル化したデータを保存するデータベース」のことです。一般的にウェブアプリケーション開発でのデータベースといえば RDMBS や DynamoDB などが挙げられますが、Vector store に関してはベクトル化したデータを効率的に保存したり検索することに特化したデータベースになります。
では、このベクトル化したデータはどのように保存・検索できるのでしょうか?
例えば、以下のような自然言語をベクトル化する場合、ベクトルデータへの変換を行う専用のアルゴリズムが活用され、変換されます(※自然言語のベクトルデータ化の詳細について興味がある方は、 Word2Vec や Doc2Vec というキーワードで調べてみてください。ただし、RAGを活用する上での理解には役立ちますが、必須となる知識ではありません) 。
猫: [ 0.2, 0.5, -0.3, 0.1, 0.7 ]
犬: [ 0.3, 0.4, -0.2, 0.2, 0.6 ]
家: [ -0.1, 0.8, 0.4, -0.3, 0.2 ]
車: [ 0.6, -0.2, 0.1, 0.7, -0.4 ]これだけ見ると関連性が見えにくいですが、類似している単語については例えば以下のように変換されます。
a) "りんご" と "みかん"
"りんご" のベクトル: [0.4, 0.2, -0.3, 0.6, -0.1]
"みかん" のベクトル: [0.5, 0.3, -0.2, 0.5, -0.2]
b) "走る" と "歩く"
"走る" のベクトル: [-0.2, 0.7, 0.4, -0.1, 0.3]
"歩く" のベクトル: [-0.3, 0.6, 0.5, -0.2, 0.2]Vector store は、このようにベクトルデータの間の距離を計算して類似度に基づいた検索結果を出してくれます。上記のベクトルデータの例では5次元で表現されていますが、実際の埋め込みはより高次元(例:50、100、300次元など)であることが一般的です。
RAG を活用するにあたって、ここまで詳細な知識としての備えは不要ですが、LangChain を含め生成 AI のライブラリは高度に抽象化されているため、概念として理解しておくと楽になることが多いです。一方で、概念レベルでも理解がないと使い方のイメージができず行き詰まってしまうことが多いので、表面的であっても処理の流れをイメージできるようにしておくことがおすすめです。
この Vector store に、あらかじめ用意した知識コンテンツのデータをベクトル化して保存する処理のことを「Embedding」と言います。また、Amazon Bedrock では Embedding を行うために与えた情報をベクトルデータに変換してくれるモデルが提供されています。LangChain ではソースとなるデータを読み込み、モデルを指定してベクトル化を行い、Vector store に保存してくれるインターフェースが提供されています。
RAG の実装は、このように「ソースデータを読み込んでVector store に保存」し、「質問と類似した情報検索」を行い、「質問と検索結果をセットで LLM に投げて回答を作ってもらう」流れで対応します。
作りたいこと
それでは、RAG 構成を適用して、事前に用意した情報を基に回答してくれる Q&A のサンプルを作っていきます。まずは、以下のテキストデータのファイル( sample.txt )をソースデータとして知識コンテンツ(Vector store)に保存します。
2024年の新宿駅1日平均乗降者数は347,825名でした。
2024年の池袋駅1日平均乗降者数は224,581名でした。
2024年の上野駅1日平均乗降者数は113,327名でした。そして、この情報をもとに、2024年の新宿駅の乗降者数について回答してもらうようにします。
質問:
2024年の新宿駅の乗降者数の平均を教えてください。
回答:
提供された情報によると、2024年の新宿駅の1日平均乗降者数は347,825名でした。RAG 構成と処理の流れ①「Embedding」実装例
以下の構成を参考として、ソースデータを読み込み、 Embedding していきます。「Titan Text Embeddings」とある部分は、Amazon Bedrock で提供されているテキストデータの Embedding 専用のモデルになります。
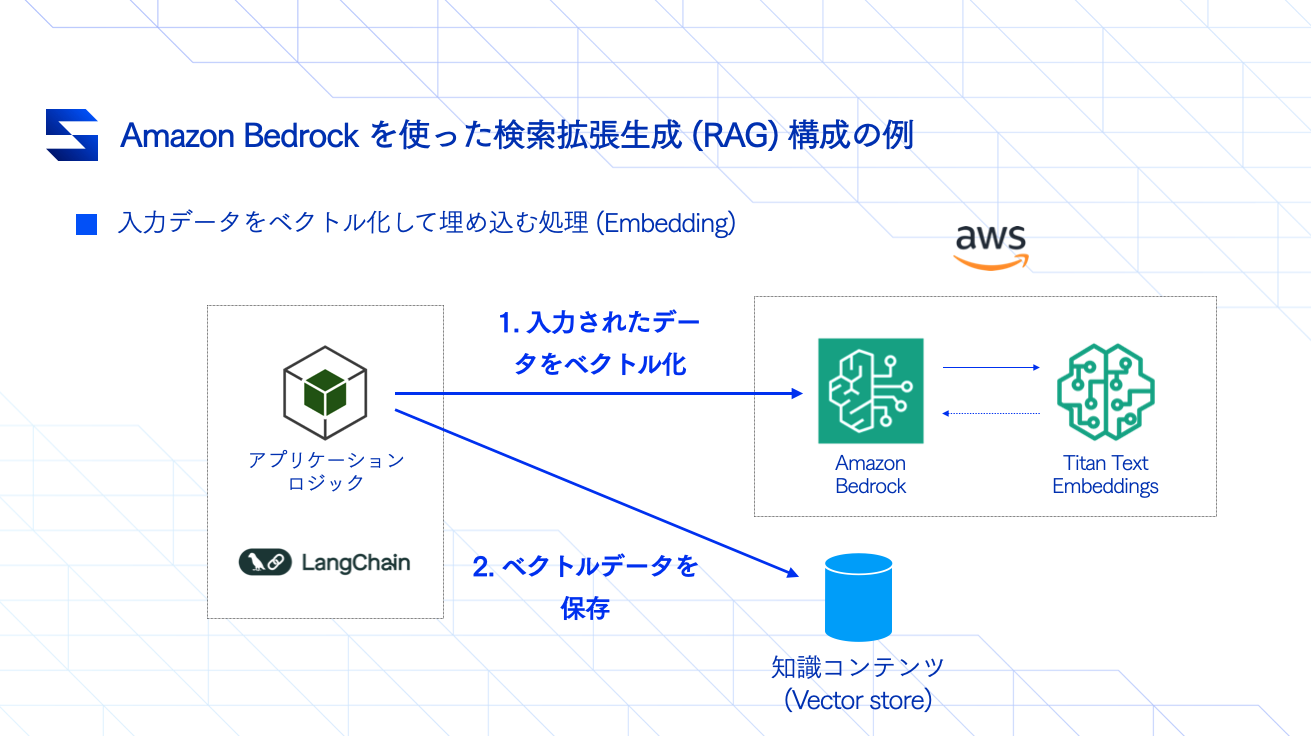
まずは、今回のサンプルで利用する OSS Vector store の「ChromaDB」を入れます。通常、Vector store は以下のような選択肢がありますが、
- Pinecone や TiDB といったサードパーティのソリューションやサービスを利用
- Amazon OpenSearch Service, MongoDB など NoSQL Database
- Amazon Aurora でも利用することが可能
今回は、サンプルとして、別途費用がかからず、サーバーホスティングやサービス登録等が不要な OSS の ChromaDB をローカルで利用することにします。
※冒頭にも記載しておりますが、Amazon Bedrock や LangChain に関する基本的な理解、環境のセットアップについては前回の記事をご参照ください。
$ source .venv/bin/activate
(.venv) $ pip install chromadb langchain_chroma langchain_text_splittersソースデータ sample.txt を用意します。後ほど説明しますが、質問内容と関連性の高い部分を効率よく検索できるようにするために、ソースデータの分割を行いますので、改行を1行ずつ挟んだ形にしてください(※通常はそこまでソースデータのフォーマットに注意する必要はありませんが、サンプルでは分かりやすく処理内容を表現するためにこのようにしています。実務ではデータ量が膨大になることが多く、分割単位は 1KB またはそれ以上になることが多いです。)
2024年の新宿駅1日平均乗降者数は347,825名でした。
2024年の池袋駅1日平均乗降者数は224,581名でした。
2024年の上野駅1日平均乗降者数は113,327名でした。 embedding.py を作成し、以下のように書いていきます。
import boto3, chromadb, pprint
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import CharacterTextSplitter
from langchain_aws import BedrockEmbeddings
from langchain_chroma import Chroma
# ソースデータをベクトルデータに変換してくれるモデルを指定して、embedding オブジェクトを作成します。
# 事前に Amazon Bedrock のコンソールからアクセス権が有効になっていることを確認してください。
# →「環境確認③ Bedrock で利用するモデルのアクセス申請を行う」
# https://serverless.co.jp/blog/n7m9v6cgvkz/
embeddings = BedrockEmbeddings(
client=boto3.client("bedrock-runtime", region_name="us-west-2"),
model_id="amazon.titan-embed-text-v1",
region_name="us-west-2"
)
# ベクトルデータを保存してくれる Vector Store のオブジェクトを作成します。
# 本文で記載したように「ChromaDB」という OSS 製品を利用します。
# 他にも LangChain がサポートする様々な種類の Vector Store があります。詳細はこちらをご確認ください。
# https://python.langchain.com/v0.1/docs/modules/data_connection/vectorstores/
vectorstore = Chroma(
# 登録するデータのコレクションを指定することが可能です。サンプルでは'simple_rag_sample'とします。
# 様々な種類のデータを扱うときは、Collection を指定して格納するデータや検索範囲を分離させることができます。
# Collection の他、metadata を使ってフィルタリングする方法もありますが、そこは適宜使いやすい方を選びます。
collection_name='simple_rag_sample',
# Embedding を行ってくれるオブジェクトを指定します。
embedding_function=embeddings,
# ChromaDB は登録したデータをローカルにファイル書き込みして利用することが可能です。
# 本番向けでは非推奨の機能ですが、RAGを検証するには十分ですのでこちらを利用します。
# 実行すると、'.tmp/' ディレクトリが作成され、そこにデータが書き込まれるようになります。
client=chromadb.PersistentClient(path='.tmp/')
)
# Embedding は、一気に大量のデータを書き込むより、一定のサイズや分脈ごとに分割して行う方が検索効率や精度が高くなります。
# サンプルでは、テキストのソースデータを 1行ずつ読み込ませるため、chunk_size を 30 にしました。
# chunk_overlap(分割単位を跨いで含めることができるサイズ上限)は、特に不要なので 0 を指定します。
text_splitter = CharacterTextSplitter(chunk_size=30, chunk_overlap=0)
# ソースデータを読み込み、分割して document という単位のデータに変換します。
source_text = TextLoader('sample.txt').load()
documents = text_splitter.split_documents(source_text)
print('\nソースデータの分割結果: \n')
pprint.pprint(documents)
# Vector store に document を登録します。
vectorstore.add_documents(
documents=documents,
embedding=embeddings
)
# 登録されたドキュメントがキーワードに合わせて検索で引き出せるかを確認します。
# k=3 にすると、検索結果を 3 つまで返します。
# その他パラメータ情報の詳細については、こちらをご参照ください。
# https://api.python.langchain.com/en/latest/vectorstores/langchain_chroma.vectorstores.Chroma.html#langchain_chroma.vectorstores.Chroma.similarity_search_with_score
result = vectorstore.similarity_search_with_score(query='新宿駅', k=3)
print('\n「新宿駅」での検索結果: \n')
pprint.pprint(result)それでは、結果を確認してみます。以下のような形で出力されていればOKです。
# 実行前に AWS 認証情報の指定を忘れないでください。
$ python embedding.py
# 3つの Document に分割されていることが分かります。
ソースデータの分割結果:
[Document(metadata={'source': 'sample.txt'}, page_content='2024年の新宿駅1日平均乗降者数は347,825名でした。'),
Document(metadata={'source': 'sample.txt'}, page_content='2024年の池袋駅1日平均乗降者数は224,581名でした。'),
Document(metadata={'source': 'sample.txt'}, page_content='2024年の上野駅1日平均乗降者数は113,327名でした。')]
# 「新宿駅」というキーワードと最もベクトル値が近いものから表示されます。
# "413.52000345792607" がそのスコアになります。
「新宿駅」での検索結果:
[(Document(metadata={'source': 'sample.txt'}, page_content='2024年の新宿駅1日平均乗降者数は347,825名でした。'),
413.52000345792607),
(Document(metadata={'source': 'sample.txt'}, page_content='2024年の池袋駅1日平均乗降者数は224,581名でした。'),
489.25846159310566),
(Document(metadata={'source': 'sample.txt'}, page_content='2024年の上野駅1日平均乗降者数は113,327名でした。'),
490.5823538330433)]この記事ではわかりやすくする目的で3行のみのテキストデータを使用しましたが、他にも CSV、HTML、JSON、Markdown、PDFなどさまざまなタイプのデータをソースとして利用できます。LangChain からサポートされている他の Document Loader はこちら(https://python.langchain.com/v0.2/docs/how_to/#document-loaders)で確認できます。
Embedding 利用時も、ベクトルデータ変換を行う際のモデルの利用料金が発生します。今回利用している Embedding 用のモデル amazon.titan-embed-text-v1 については、コードで出力するための便利な Callback メソッドが用意されていないため出力していないですが、こちら(https://huggingface.co/spaces/Xenova/the-tokenizer-playground)で text-embedding-ada-002 (※OpenAI の Embedding モデル)を選択してトークン数の参考値を出してみることは可能です。両方とも $0.0001 per 1k token という価格設定なので、物によりますが、サンプル実装のみならずほとんどのケースで Embedding の料金が気になることはあまりないかと思います。
RAG 構成と処理の流れ②「Retriever」実装例
続いて、前項で Embedding した内容に基づいて回答を生成する部分を実装していきます。ここでは、LangChain の「Retriever」という機能を使います。「Retrieve」という英単語は元々取り戻す、回収するするという意味があり、例えば「ゴールデン・レトリーバー」 という犬種の名前についているものも同じ言葉になります。ゴールデン・レトリーバーは「獲物を回収する」といった由来になるかと思いますが、今回は情報を回収するという意味で理解していただけると分かりやすいかと思います。
import boto3, chromadb, pprint
from langchain_aws import BedrockEmbeddings, ChatBedrock
from langchain_chroma import Chroma
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
from langchain_community.callbacks.manager import get_bedrock_anthropic_callback
# llm の各パラメータの詳細は前回の記事をご参考ください。内容は前回と同じです。
# https://serverless.co.jp/blog/n7m9v6cgvkz/
llm = ChatBedrock(
region_name="ap-northeast-1",
model_id="anthropic.claude-3-5-sonnet-20240620-v1:0",
model_kwargs={
"max_tokens": 1000,
"temperature": 0.1
}
)
# Vector store を利用するための Embedding オブジェクトを作成します。
# 各パラメータの詳細は前項「RAG 構成と処理の流れ①「Embedding」実装例」をご参考ください。
# 内容は前項と同じです。
embeddings = BedrockEmbeddings(
client=boto3.client("bedrock-runtime", region_name="ap-northeast-1"),
model_id="amazon.titan-embed-text-v1"
)
# 事前に登録した情報を引き出すため Vector store のオブジェクトを作成します。
# 各パラメータの詳細は前項「RAG 構成と処理の流れ①「Embedding」実装例」をご参考ください。
# 内容は前項と同じです。
vectorstore = Chroma(
collection_name='simple_rag_sample',
embedding_function=embeddings,
client=chromadb.PersistentClient(path='.tmp/')
)
# LLM にどのように質問を処理してほしいかを具体的に書く「指示文(=プロンプト)」のテンプレートです。
# {question} に質問内容が入ります。
# {context} に、前項で試した検索結果 document の内容が入ります。
# LLM は、この全体が埋まった形の指示分を受け取り、context の内容に基づいて question の回答を生成してくれます。
prompt_qa = PromptTemplate(
template="""
日本語で、質問に関連する内容を以下の関連情報を基に回答してください。
{context}
質問: {question}
回答:
""",
input_variables=["context", "question"]
)
# LamgChain の「RetrievalQA」を利用し、Vector store から情報を retrieve した上、
# 上記 のPromptTemplate に context と question を埋め込んでくれます。
# search_kwargs={"k": 3} については、前項と同じく検索結果で受け取る document の数を指定します。
# search_kwargs の詳細については以下のリンクをご参照ください。
# https://api.python.langchain.com/en/latest/vectorstores/langchain_chroma.vectorstores.Chroma.html#langchain_chroma.vectorstores.Chroma.as_retriever
retrieval_qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type='stuff',
retriever=vectorstore.as_retriever(search_kwargs={"k": 3}),
chain_type_kwargs={"prompt": prompt_qa}
)
# get_bedrock_anthropic_callback については前回の記事をご参考ください。内容は同じです。
# https://serverless.co.jp/blog/n7m9v6cgvkz/
with get_bedrock_anthropic_callback() as callback:
# ここまでで、RAG を検証するための準備が全て整いました。
# retrieval_qa.invoke('質問内容') を呼ぶことで、回答を受け取ることができます。
result = retrieval_qa.invoke("2024年のJR新宿駅の乗降者数の平均を教えてください。")
print('\n質問:\n', result['query'])
print('\n回答:\n', result['result'])
print('\n レポート:', callback)
それでは、結果を確認してみます。以下のような形で出力されていればOKです。
# 実行前に AWS 認証情報の指定を忘れないでください。
$ python retriever.py
質問:
2024年の新宿駅の乗降者数の平均を教えてください。
回答:
提供された情報によると、2024年の新宿駅の1日平均乗降者数は347,825名でした。
これは新宿駅全体の数字であり、JR新宿駅に限定した数字ではないことに注意が必要です。新宿駅は複数の鉄道会社が乗り入れる大規模な駅であり、この数字にはJR線以外の私鉄やメトロの利用者も含まれている可能性が高いです。
JR新宿駅のみの正確な乗降者数は提供された情報からは分かりません。JR新宿駅単独の数字を知りたい場合は、JR東日本などの公式な情報源から直接データを確認する必要があります。
レポート: Tokens Used: 385
Prompt Tokens: 159
Completion Tokens: 226
Successful Requests: 1
Total Cost (USD): $0.0038669999999999998質問を変えてみます。今度は、「新宿駅」→「品川駅」に変更してみます。与えていない情報について質問すると、以下のような形で返ってきます。
# 実行前に AWS 認証情報の指定を忘れないでください。
$ python retriever.py
質問:
2024年の品川駅の乗降者数の平均を教えてください。
回答:
申し訳ありませんが、提供された情報の中に2024年の品川駅の乗降者数に関するデータがありません。新宿駅、池袋駅、上野駅の乗降者数は記載されていますが、品川駅については言及されていません。
そのため、2024年の品川駅の1日平均乗降者数を正確にお答えすることはできません。品川駅の具体的な数字を知るためには、追加の情報や統計データが必要となります。
ご質問の回答に必要な情報が不足していることをご了承ください。
レポート: Tokens Used: 336
Prompt Tokens: 156
Completion Tokens: 180
Successful Requests: 1
Total Cost (USD): $0.003168以上、簡単な RAG の実装例ではありますが、その概念や用語が慣れないうちはどのように実装に取り掛かれば良いか迷うこともあるかと思います。本記事を参考に是非チャレンジしてみていただければと思います。社内ドキュメント検索から、各種手続きやマニュアル、その他 Q&A 形式のものであれば幅広いユースケースで活用することができます。
この記事に関する内容を含め、AWSと生成 AI 開発全般において気になる点やサポートが必要な場合は、お気軽にお問い合わせください。