

概要
AWSでサーバーレスアーキテクチャでアプリケーションを構築する際、多くの場合はたくさんのLambdaやフルマネージドサービスで構成されることになります。その際にどういったディレクトリ構成でどのようにソースコードを構成してCI/CDを回していけばよいかをこの記事では書いています。
結論としては、Serverless Enterprise Application Boilerplate For Pythonに実際のソースコードとしてまとめていますので、より詳細はこちらを確認してもらえればと思います。
使用しているサービスとツール
本記事ではCI環境としてCircleCIを使っています。GitHub ActionsやCodeBuildでも同じようなことが可能なはずなので、これらは好みで選べば良いでしょう。
また、デプロイツールとしてServerless Frameworkを使っています。SAMでもCDKでも大体同じことは可能なので、どれを選ぶかは好みを最優先して良いでしょう。
以降、これらのデプロイツールを使うと最終的にはCloudFormationに展開されるので、CloudFormationの前提で記述します。
アプリケーション内部でサービスを分割しよう
冒頭でも述べたとおり、エンタープライズなアプリケーションになるとたくさんのAWSサービスを構成管理する必要があります。それをひとつのファイルで管理するのは流石に無理があるため、細かくサービスの単位に分割して構成管理をするようにします。分割した単位でCloudFormationの1スタックがデプロイされるイメージです。
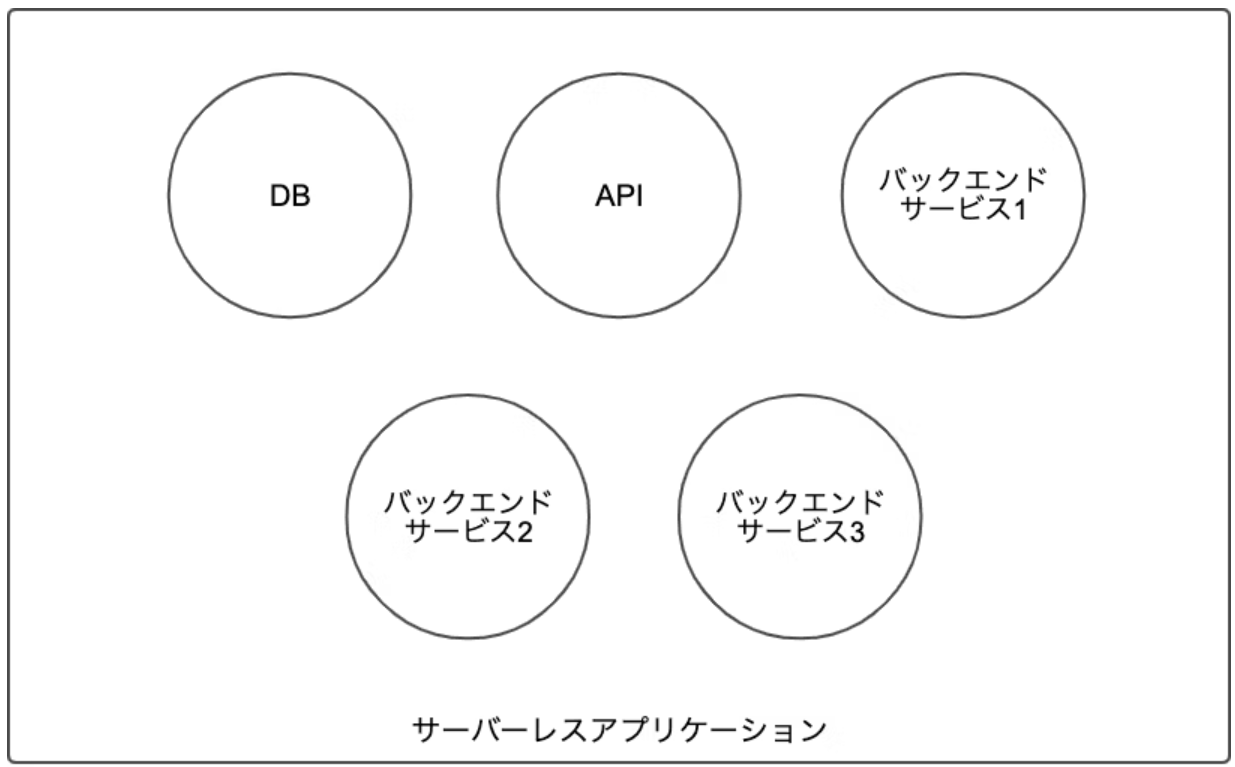
まずポイントとしてはステートを持つサービスと持たないサービスを明確に分離します。DynamoDBやS3のようなデータを永続化させるサービスとLambdaのようにデータを永続化しないサービスは当然デプロイのサイクルも頻度も違います。それらが違うものは明確に分離させたほうがいいでしょう。
そしてアプリケーションの入り口となるAPI達は1つのスタックにしてしまいます。残りのバックエンドで処理をしてくれるものは処理として完結できる意味のある単位で分けるのが良いでしょう。そしてそれぞれのバックエンドサービス間で値のやり取りが発生するケースも多いと思うので、どのようにそれらのサービス間でデータを受け渡しするのかも考えておきましょう。
具体的に考えられるデータの受け渡し方法は以下のとおりです。
- EventBridgeやSQSにデータをPublishして引き継ぐ
- DBに値を入れておいて、別のサービスからデータをポーリングして受け取る
- API Gatewayでhttpエンドポイントを用意してそこにデータを渡す
- S3を使用してのファイル連携
ディレクトリ構成
Serverless Enterprise Application Boilerplate For Pythonを見てもらえるとわかるかと思いますが、以下のようなルールでディレクトリ構成を決めます
ディレクトリ | 用途 |
|---|---|
layer | Lambda Layerとしてデプロイする外部のライブラリや共通処理として定義したコードを参照先としてlayerとなるCloudFormationを定義します。 |
resources | DynamoDBやS3、SSMなどデータを保持するサービスのCloudFormationを定義します。 |
lib | 共通処理として定義したコードを定義します。これらはLambda Layerとしてデプロイします。 |
services | 1つ前のセクションで分割した各サービスを格納します。1サービス1CloudFormationスタックの単位で定義していきます。 |
tests | テストコードを格納します。ユニットテストとインテグレーションテストが主に入ります。 |
サービス間での値の参照
細かくサービスやリソースの単位でCloudformationを分割するので、当然ながらDBのTable名やArnの値は複数のサービスから参照させる必要があります。
その場合はCloudFormationのクロススタック出力やServerless Frameworkであれば、Reference CloudFormation Outputsの機能を使うことでスタック間で値を参照できます。
なので、外部のスタックから参照させたい値はCloudFormationのOutPutsに出力して参照できるようにしておきましょう。
CloudFormationのImportValueの機能を使えば以下の様に書くことで値が参照できます。
Fn::ImportValue: <Export名>また、Serverless Frameworkの機能を使うと以下のように記述できます
${cf.<リージョン名>:<CloudFormationスタック名>.<output名>}
tableArn: ${cf.ap-northeast-1:dev-stack.tableArn}テストの方針
サーバーレスアプリケーションを作る上での多くのケースではユニットテストとインテグレーションテストの2パターンを行います。
ユニットテストは通常のアプリケーションで実行するユニットテストです。インテグレーションテストは実際にAWS環境にデプロイしてその実行結果をテストします。
インテグレーションテストを必ず行うことがサーバーレスアプリケーションでは特徴的かもしれません。どうしても分散型のアプリケーションではユニットテストだけではテストをやりきることが難しいです。実際にユニットテストが通ってもIAMの設定が足りずに動かないかもしれません。そういったクラウド独自の仕組みも含めて処理が完了することを確認するためにインテグレーションテストを行います。
基本的には正常系を1パターン以上インテグレーションテストを記述します。そして内部的なバリデーション等のロジックをユニットテストでカバーするのが良いでしょう。
例えばAPIのインテグレーションテストのCIの設定例を見てみましょう。「Deploy API for integration test」のフェーズでAWS環境に必要なリソースをデプロイします。その後「Run API integration test」で実際にAWS上で期待通りの動作をするかのテストを行います。
api_test:
executor:
name: default
steps:
- attach_workspace:
at: ~/workspace
- run: *install_sls
- run:
name: Deploy API for integration test
command: |
. venv/bin/activate
yarn deploy:db
yarn deploy:layer
yarn deploy:api
environment:
STAGE: 1
- run:
name: Run API integration test
command: |
. venv/bin/activate
yarn test:api
environment:
STAGE: 1AWSアカウントの分け方
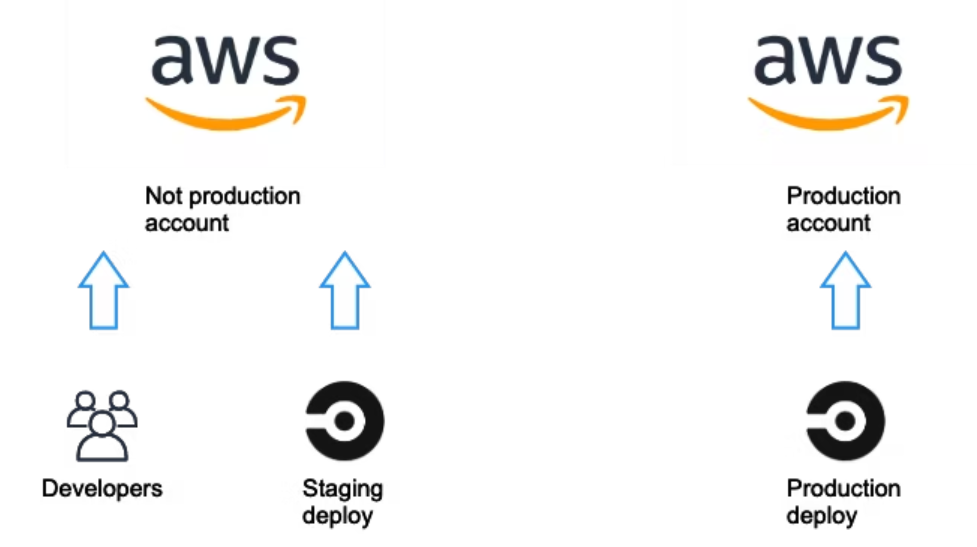
サーバーレスアプリケーションでなくてもこれは同様かと思いますが、本番とそれ以外の環境でアカウントを分離します。
本番でないアカウントの方では各開発者ごとの環境とステージングの環境が存在します。Serverless FrameworkであればStageの機能を使ってこれらの環境を切り分けるのが良いでしょう。そして、本番とそれ以外のデプロイ先の切り替えはCircleCIのContextの機能を使います。
この機能を使えば条件に応じて適用する環境変数のセットを切り替えることが出来るので、それを利用してアカウントの切り替えを行います。
CI/CDパイプライン
ステージング及び本番についてはCI環境から自動デプロイを行います。以下のような条件で自動デプロイを設定します。
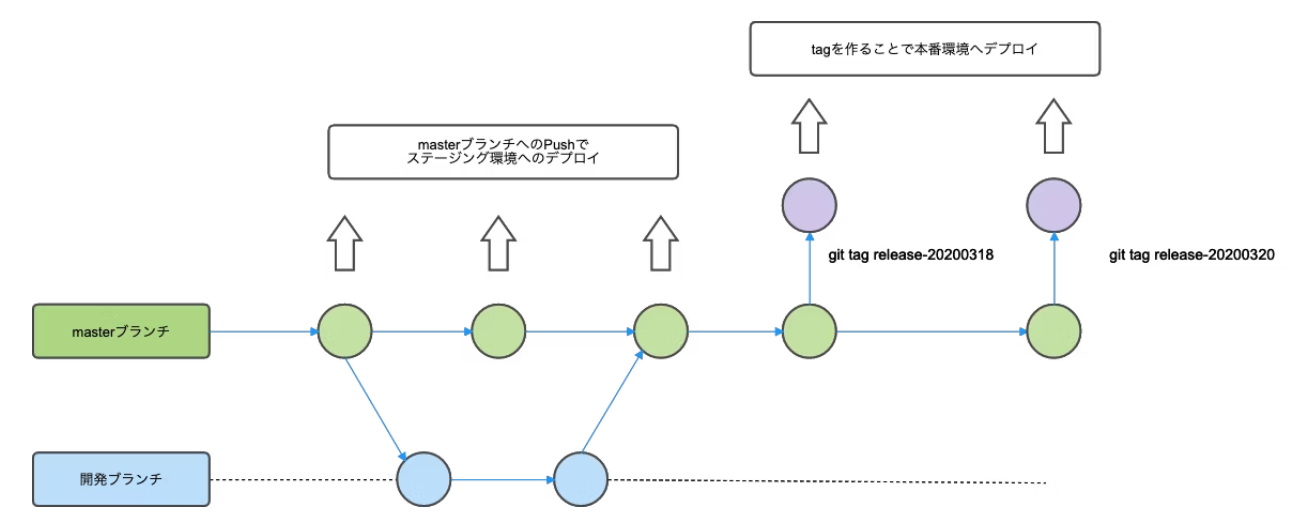
以下は具体的にmasterブランチにマージされた際のCircleCIのワークフローになります。
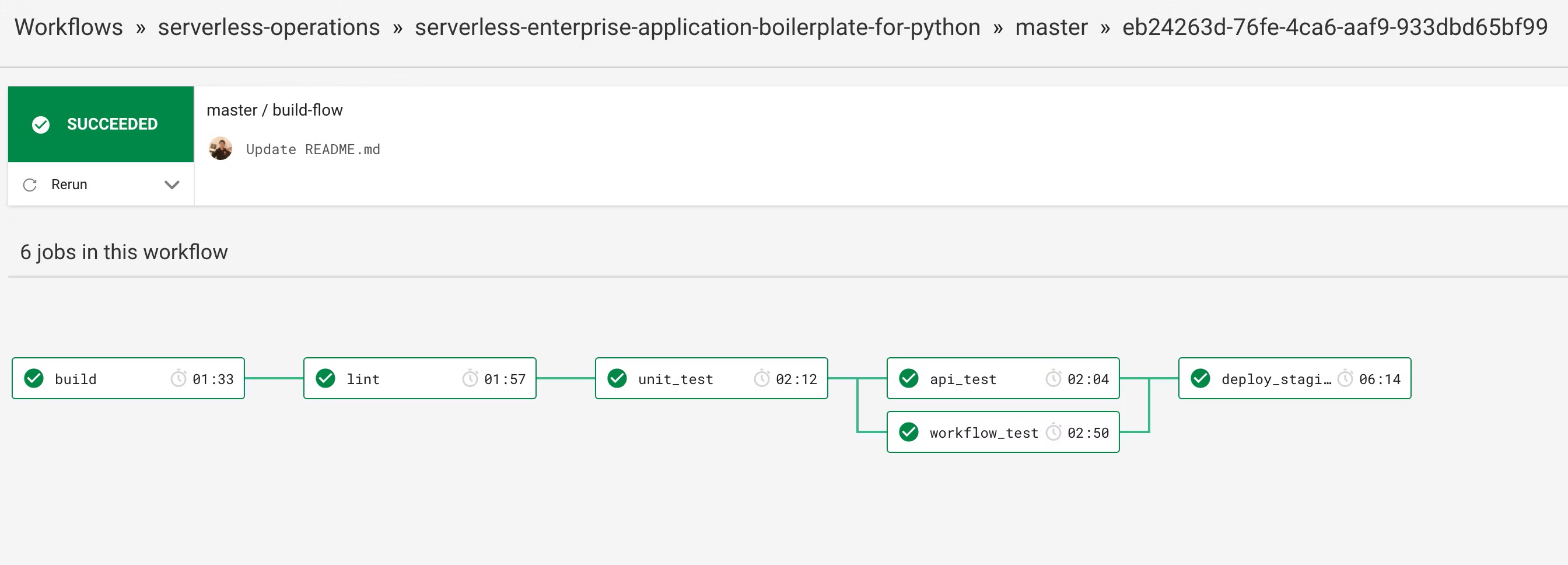
以下のような順でワークフローを定義しています。
1. 環境のセットアップ
2. Lintによる構文チェック
3. ユニットテスト
4. インテグレーションテスト
5. ステージングへのデプロイ