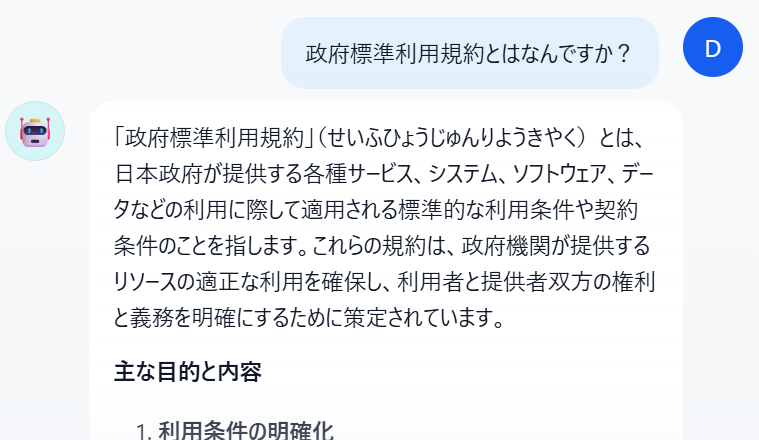
今日は前回に引き続きRAGを作っていきます。
先日Notionを検索ソースとする記事を公開しましたが、この記事では改めてはじめてDifyを触る人向けにPDFを読み込んで検索ソースとするRAGを作る手順をまとめていきます。
まずそのまえに:RAGとは?
RAGとは、Retrieval-Augmented Generation(検索拡張生成)の略で、主に生成AI(特に大規模言語モデル)に外部知識を組み合わせて回答の精度や信頼性を向上させる仕組みを指します。
生成AIは学習用データ収集ボットが収集したデータを学習しますが、当然ですが、インターネット上に存在していない情報は学習できません。このため、顧客情報や社内規約などはLLMモデルは理解していない状態になります。
そこに対して外部のデータソース(Difyではこれをナレッジと呼びます)を組み合わせることで、従来の全文検索の仕組みを生成AIを活用して、自然な回答を作ってくれることを実現します。
これはシンプルな構成の場合以下のステップで動作します
1.事前準備:
あらかじめ検索対象とする文章をチャンクというサイズに区切ってベクトル化させ、ナレッジに保存します。この際元の言葉とペアで保存しておきます。
2.検索
検索された文言(LLMの世界ではプロンプトと呼びます)をリアルタイムでベクトル化させて、上記のベクトルと突き合わせ近いものを判定します。
3.最終的な回答作成
近いベクトルとペアで保存されている言葉(チャンク)を取り出して生成AIに自然な回答の作成を依頼し、最終的に出来上がったものが検索者に回答として出力されます。
従来であればこれらのステップをプログラミングで組み込んでいく必要がありましたが、Difyを使うとノーコードで実現できます。
さっそくやってみる
事前準備
まず前回の記事の内容を終わらせてシンプルなチャットボットが動く状態まで設定しておきます。
ナレッジの作成
画面上部のナレッジをクリックします。

ナレッジベースを作成をクリックします。
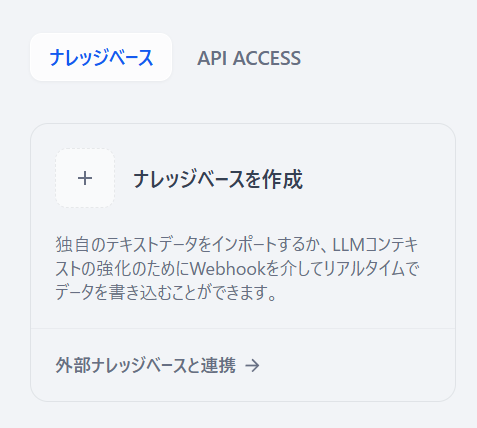
何か任意のPDFをアップロードして次へをクリックします。
何でもよいですが例えば
をダウンロードして使います。
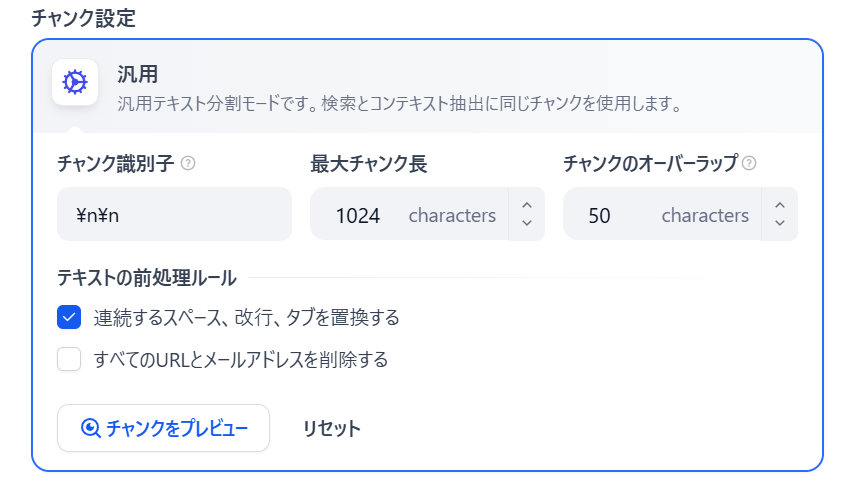
文章をチャンクに分割してベクトル化させます。この場合文章は
1.改行が2つ入っている(ほとんどの場合段落がそうなっている)
2.1024文字単位
のどちらかの条件に合致した場合一つのチャンクとして切り出されます。
例えば対象がPDFではなくマークダウンの場合、###などが段落として使われますので、適宜読み込ませる文章用に書き換えていきます。
オーバーラップですが、チャンクに区切られた文章はお互いの相関性を基本持ちません。このため相関性を持たせるために、わざと前後を少し重ねてベクトル化することで、重複した部分がベクトルデータの世界で完成性(文章前後等)を保持することを期待したパラメータです。
あとは保存して処理をクリックすると以下の通り処理待ちとなるので待ちます。
完了すると以下の通りとなります。
これでナレッジが完成しました。
RAGの構築
ではいよいよRAGの構築です。
画面上部でスタジオをクリックします。

テンプレートから作成をクリックします。

知識リトリーバル+チャットボットを作成します。
初回はOpenAIのプラグインインストール画面が出てくると思いますので許可しておきます。
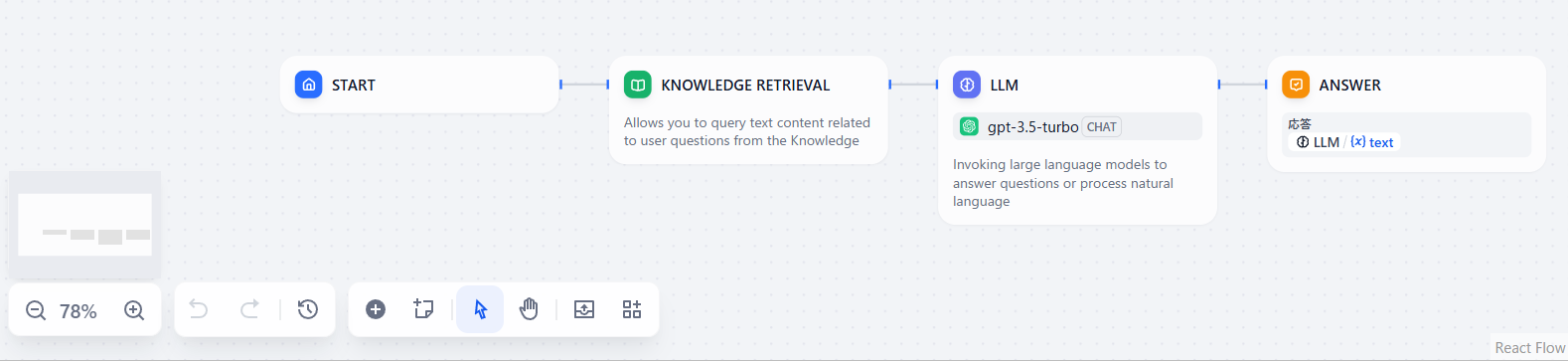
こんな感じのアプリケーションがワークフローとして出来上がっています。
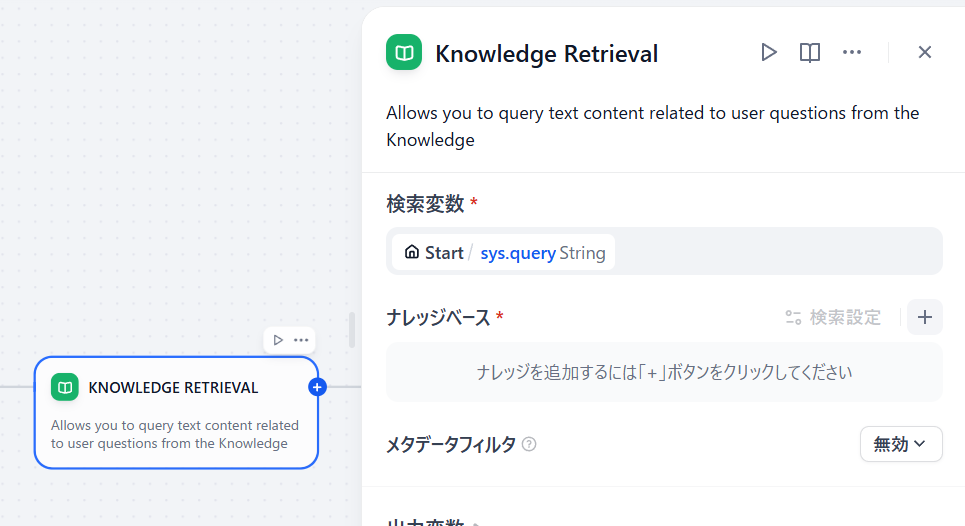
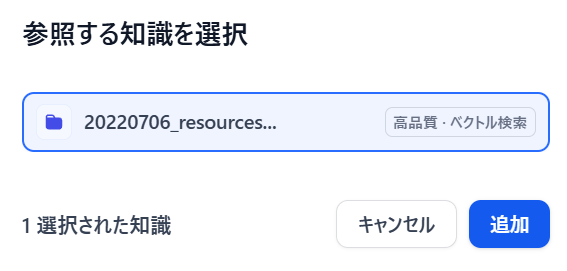
KNOWLEDGE RETRIEVALをクリックして先ほど作成したナレッジを指定します。
あとはプレビューをクリックして会話するだけです。
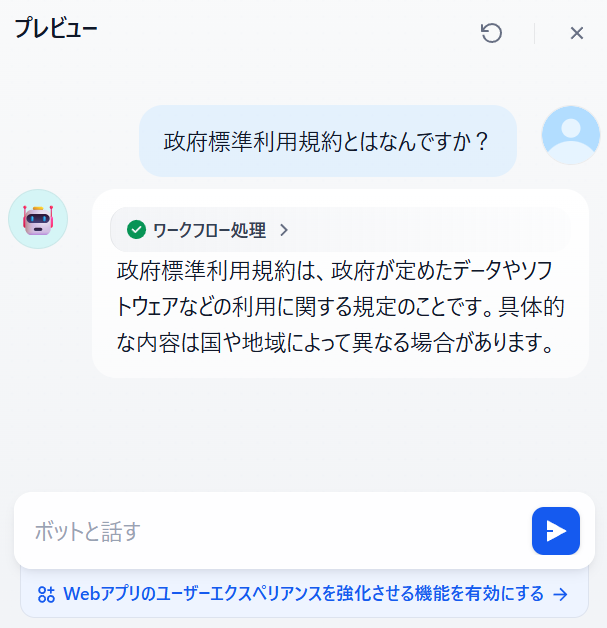
前回の手順で作成したチャットボットにも同じ質問を投げてみて、異なる回答が戻ることを確認してみてください。