

前回の記事で新しくリリースされたAurora DSQL を起動してLambdaから接続を行ってみました。この記事では追加シナリオでDSQL用MCP Server を試してみます。
https://serverless.co.jp/blog/3fgjxbqcki/
AWS Serverless MCP Server(サーバレスとサーバが両方入っている・・・)を試した時にAWSのMCP Serverは基本Python出て提供されuvxで起動する形態をとっているためWindows環境ではそのまま動作しないため、起動手順に少し修正が必要でした。
このDSQL用MCP Serverはpyスクリプトも改修が必要でしたので以下にWindows版の手順をまとめておきます。

環境変数を使わずコードそのものの修正で対応しました。
さっそくやってみる
環境準備
まずは前回の記事に基づきDSQLを起動しておきます。
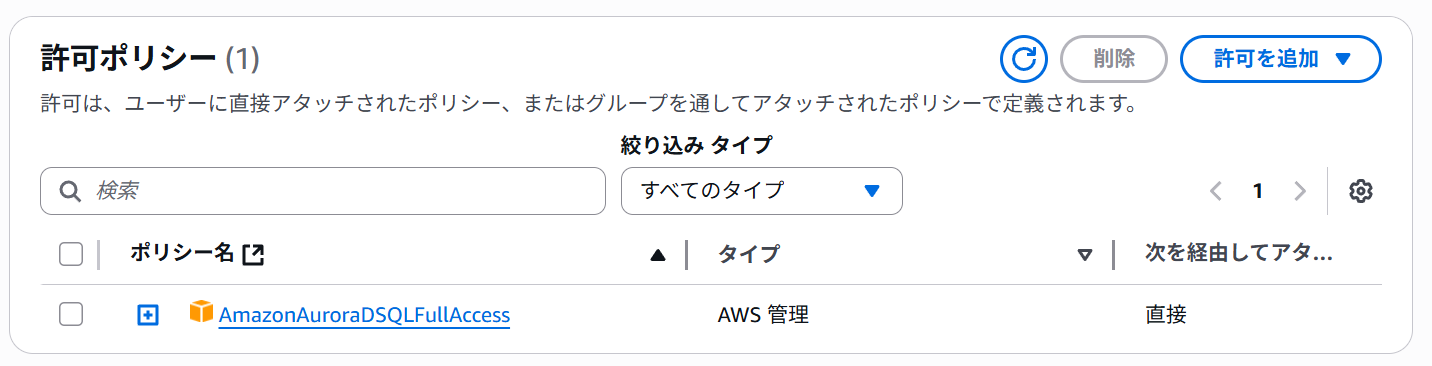
次にこの記事の内容に従いIAMユーザーを準備しaws configureでdefaultプロファイルにクレデンシャルをセットしておきます。ポリシーは以下をセットしました。
DSQL 用MCP Serverの環境構築(+Windows用修正)
公式手順はこちらです。
https://awslabs.github.io/mcp/servers/aurora-dsql-mcp-server/
まずはgitからコードをクローンします。
git clone https://github.com/awslabs/mcp.git
cd mcp/src/aurora-dsql-mcp-serverWindows専用の環境依存問題を解決するためserver.pyを以下に入れ替えます。
# Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""awslabs Aurora DSQL MCP Server implementation."""
import argparse
import asyncio
import boto3
import platform
import psycopg
import sys
from awslabs.aurora_dsql_mcp_server.consts import (
BEGIN_READ_ONLY_TRANSACTION_SQL,
BEGIN_TRANSACTION_SQL,
COMMIT_TRANSACTION_SQL,
DSQL_DB_NAME,
DSQL_DB_PORT,
DSQL_MCP_SERVER_APPLICATION_NAME,
ERROR_BEGIN_READ_ONLY_TRANSACTION,
ERROR_BEGIN_TRANSACTION,
ERROR_CREATE_CONNECTION,
ERROR_EMPTY_SQL_LIST_PASSED_TO_TRANSACT,
ERROR_EMPTY_SQL_PASSED_TO_READONLY_QUERY,
ERROR_EMPTY_TABLE_NAME_PASSED_TO_SCHEMA,
ERROR_EXECUTE_QUERY,
ERROR_GET_SCHEMA,
ERROR_QUERY_INJECTION_RISK,
ERROR_READONLY_QUERY,
ERROR_ROLLBACK_TRANSACTION,
ERROR_TRANSACT,
ERROR_TRANSACT_INVOKED_IN_READ_ONLY_MODE,
ERROR_TRANSACTION_BYPASS_ATTEMPT,
ERROR_WRITE_QUERY_PROHIBITED,
GET_SCHEMA_SQL,
INTERNAL_ERROR,
READ_ONLY_QUERY_WRITE_ERROR,
ROLLBACK_TRANSACTION_SQL,
)
from awslabs.aurora_dsql_mcp_server.mutable_sql_detector import (
check_sql_injection_risk,
detect_mutating_keywords,
detect_transaction_bypass_attempt,
)
from loguru import logger
from mcp.server.fastmcp import Context, FastMCP
from pydantic import Field
from typing import Annotated, List
# Windows環境での対応を最優先で実施
def setup_windows_compatibility():
"""Windows環境でのasyncio/psycopg互換性を設定"""
if platform.system() == 'Windows':
# ProactorEventLoopの問題を回避
try:
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
logger.info("Windows SelectorEventLoop policy set successfully")
except Exception as e:
logger.warning(f"Failed to set Windows event loop policy: {e}")
# 現在のイベントループを確認・設定
try:
loop = asyncio.get_event_loop()
if loop.is_closed():
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
except RuntimeError:
# イベントループが存在しない場合は新しく作成
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
logger.info("New event loop created for Windows")
# プログラム開始時にWindows互換性を設定
setup_windows_compatibility()
# Global variables
cluster_endpoint = None
database_user = None
region = None
read_only = False
dsql_client = None
persistent_connection = None
aws_profile = None
mcp = FastMCP(
'awslabs-aurora-dsql-mcp-server',
instructions="""
# Aurora DSQL MCP server.
Provides tools to execute SQL queries on Aurora DSQL cluster'
## Available Tools
### readonly_query
Runs a read-only SQL query.
### transact
Executes one or more SQL commands in a transaction.
### get_schema
Returns the schema of a table.
""",
dependencies=[
'loguru',
],
)
@mcp.tool(
name='readonly_query',
description="""Run a read-only SQL query against the configured Aurora DSQL cluster.
Aurora DSQL is distributed SQL database with Postgres compatibility. The following table
summarizes `SELECT` functionality that is expected to work. Items not in this table may
also be supported, as this is a point in time snapshot.
| Primary clause | Supported clauses |
|---------------------------------|-----------------------|
| FROM | |
| GROUP BY | ALL, DISTINCT |
| ORDER BY | ASC, DESC, NULLS |
| LIMIT | |
| DISTINCT | |
| HAVING | |
| USING | |
| WITH (common table expressions) | |
| INNER JOIN | ON |
| OUTER JOIN | LEFT, RIGHT, FULL, ON |
| CROSS JOIN | ON |
| UNION | ALL |
| INTERSECT | ALL |
| EXCEPT | ALL |
| OVER | RANK (), PARTITION BY |
| FOR UPDATE | |
""",
)
async def readonly_query(
sql: Annotated[str, Field(description='The SQL query to run')], ctx: Context
) -> List[dict]:
"""Runs a read-only SQL query.
Args:
sql: The sql statement to run
ctx: MCP context for logging and state management
Returns:
List of rows. Each row is a dictionary with column name as the key and column value as the value.
Empty list if the SQL execution did not return any results
"""
logger.info(f'query: {sql}')
if not sql:
await ctx.error(ERROR_EMPTY_SQL_PASSED_TO_READONLY_QUERY)
raise ValueError(ERROR_EMPTY_SQL_PASSED_TO_READONLY_QUERY)
# Security checks for read-only mode
# Check for mutating keywords that shouldn't be allowed in read-only queries
mutating_matches = detect_mutating_keywords(sql)
if mutating_matches:
logger.warning(
f'readonly_query rejected due to mutating keywords: {mutating_matches}, SQL: {sql}'
)
await ctx.error(ERROR_WRITE_QUERY_PROHIBITED)
raise Exception(ERROR_WRITE_QUERY_PROHIBITED)
# Check for SQL injection risks
injection_issues = check_sql_injection_risk(sql)
if injection_issues:
logger.warning(
f'readonly_query rejected due to injection risks: {injection_issues}, SQL: {sql}'
)
await ctx.error(f'{ERROR_QUERY_INJECTION_RISK}: {injection_issues}')
raise Exception(f'{ERROR_QUERY_INJECTION_RISK}: {injection_issues}')
# Check for transaction bypass attempts (the main vulnerability)
if detect_transaction_bypass_attempt(sql):
logger.warning(f'readonly_query rejected due to transaction bypass attempt, SQL: {sql}')
await ctx.error(ERROR_TRANSACTION_BYPASS_ATTEMPT)
raise Exception(ERROR_TRANSACTION_BYPASS_ATTEMPT)
try:
conn = await get_connection(ctx)
try:
await execute_query(ctx, conn, BEGIN_READ_ONLY_TRANSACTION_SQL)
except Exception as e:
logger.error(f'{ERROR_BEGIN_READ_ONLY_TRANSACTION}: {str(e)}')
await ctx.error(INTERNAL_ERROR)
raise Exception(INTERNAL_ERROR)
try:
rows = await execute_query(ctx, conn, sql)
await execute_query(ctx, conn, COMMIT_TRANSACTION_SQL)
return rows
except psycopg.errors.ReadOnlySqlTransaction:
await ctx.error(READ_ONLY_QUERY_WRITE_ERROR)
raise Exception(READ_ONLY_QUERY_WRITE_ERROR)
except Exception as e:
raise e
finally:
try:
await execute_query(ctx, conn, ROLLBACK_TRANSACTION_SQL)
except Exception as e:
logger.error(f'{ERROR_ROLLBACK_TRANSACTION}: {str(e)}')
except Exception as e:
await ctx.error(f'{ERROR_READONLY_QUERY}: {str(e)}')
raise Exception(f'{ERROR_READONLY_QUERY}: {str(e)}')
@mcp.tool(
name='transact',
description="""Write or modify data using SQL, in a transaction against the configured Aurora DSQL cluster.
Aurora DSQL is a distributed SQL database with Postgres compatibility. This tool will automatically
insert `BEGIN` and `COMMIT` statements; you only need to provide the statements to run
within the transaction scope.
In addition to the `SELECT` functionality described on the `readonly_query` tool, DSQL supports
common DDL statements such as `CREATE TABLE`. Note that it is a best practice to use UUIDs
for new tables in DSQL as this will spread your workload out over as many nodes as possible.
Some DDL commands are async (like `CREATE INDEX ASYNC`), and return a job id. Jobs can
be viewed by running `SELECT * FROM sys.jobs`.
""",
)
async def transact(
sql_list: Annotated[
List[str],
Field(description='List of one or more SQL statements to execute in a transaction'),
],
ctx: Context,
) -> List[dict]:
"""Executes one or more SQL commands in a transaction.
Args:
sql_list: List of SQL statements to run
ctx: MCP context for logging and state management
Returns:
List of rows. Each row is a dictionary with column name as the key and column value as
the value. Empty list if the execution of the last SQL did not return any results
"""
logger.info(f'transact: {sql_list}')
if read_only:
await ctx.error(ERROR_TRANSACT_INVOKED_IN_READ_ONLY_MODE)
raise Exception(ERROR_TRANSACT_INVOKED_IN_READ_ONLY_MODE)
if not sql_list:
await ctx.error(ERROR_EMPTY_SQL_LIST_PASSED_TO_TRANSACT)
raise ValueError(ERROR_EMPTY_SQL_LIST_PASSED_TO_TRANSACT)
try:
conn = await get_connection(ctx)
try:
await execute_query(ctx, conn, BEGIN_TRANSACTION_SQL)
except Exception as e:
logger.error(f'{ERROR_BEGIN_TRANSACTION}: {str(e)}')
await ctx.error(f'{ERROR_BEGIN_TRANSACTION}: {str(e)}')
raise Exception(f'{ERROR_BEGIN_TRANSACTION}: {str(e)}')
try:
rows = []
for query in sql_list:
rows = await execute_query(ctx, conn, query)
await execute_query(ctx, conn, COMMIT_TRANSACTION_SQL)
return rows
except Exception as e:
try:
await execute_query(ctx, conn, ROLLBACK_TRANSACTION_SQL)
except Exception as re:
logger.error(f'{ERROR_ROLLBACK_TRANSACTION}: {str(re)}')
raise e
except Exception as e:
await ctx.error(f'{ERROR_TRANSACT}: {str(e)}')
raise Exception(f'{ERROR_TRANSACT}: {str(e)}')
@mcp.tool(name='get_schema', description='Get the schema of the given table')
async def get_schema(
table_name: Annotated[str, Field(description='name of the table')], ctx: Context
) -> List[dict]:
"""Returns the schema of a table.
Args:
table_name: Name of the table whose schema will be returned
ctx: MCP context for logging and state management
Returns:
List of rows. Each row contains column name and type information for a column in the
table provided in a dictionary form. Empty list is returned if table is not found.
"""
logger.info(f'get_schema: {table_name}')
if not table_name:
await ctx.error(ERROR_EMPTY_TABLE_NAME_PASSED_TO_SCHEMA)
raise ValueError(ERROR_EMPTY_TABLE_NAME_PASSED_TO_SCHEMA)
try:
conn = await get_connection(ctx)
return await execute_query(ctx, conn, GET_SCHEMA_SQL, [table_name])
except Exception as e:
await ctx.error(f'{ERROR_GET_SCHEMA}: {str(e)}')
raise Exception(f'{ERROR_GET_SCHEMA}: {str(e)}')
class NoOpCtx:
"""A No-op context class for error handling in MCP tools."""
async def error(self, message):
"""Do nothing.
Args:
message: The error message
"""
async def get_password_token(): # noqa: D103
# Generate a fresh password token for each connection, to ensure the token is not expired
# when the connection is established
if database_user == 'admin':
return dsql_client.generate_db_connect_admin_auth_token(cluster_endpoint, region) # pyright: ignore[reportOptionalMemberAccess]
else:
return dsql_client.generate_db_connect_auth_token(cluster_endpoint, region) # pyright: ignore[reportOptionalMemberAccess]
async def get_connection(ctx): # noqa: D103
"""Get a connection to the database, creating one if needed or reusing the existing one.
Args:
ctx: MCP context for logging and state management
Returns:
A database connection
"""
global persistent_connection
# Return the existing connection without health check
# The caller will handle reconnection if needed
if persistent_connection is not None:
return persistent_connection
# Create a new connection
password_token = await get_password_token()
conn_params = {
'dbname': DSQL_DB_NAME,
'user': database_user,
'host': cluster_endpoint,
'port': DSQL_DB_PORT,
'password': password_token,
'application_name': DSQL_MCP_SERVER_APPLICATION_NAME,
'sslmode': 'require',
}
logger.info(f'Creating new connection to {cluster_endpoint} as user {database_user}')
try:
persistent_connection = await psycopg.AsyncConnection.connect(
**conn_params, autocommit=True
)
return persistent_connection
except Exception as e:
logger.error(f'{ERROR_CREATE_CONNECTION} : {e}')
await ctx.error(f'{ERROR_CREATE_CONNECTION} : {e}')
raise e
async def execute_query(ctx, conn_to_use, query: str, params=None) -> List[dict]: # noqa: D103
if conn_to_use is None:
conn = await get_connection(ctx)
else:
conn = conn_to_use
try:
async with conn.cursor(row_factory=psycopg.rows.dict_row) as cur: # pyright: ignore[reportAttributeAccessIssue]
await cur.execute(query, params) # pyright: ignore[reportArgumentType]
if cur.rownumber is None:
return []
else:
return await cur.fetchall()
except (psycopg.OperationalError, psycopg.InterfaceError) as e:
# Connection issue - reconnect and retry
logger.warning(f'Connection error, reconnecting: {e}')
global persistent_connection
try:
if persistent_connection:
await persistent_connection.close()
except Exception:
pass # Ignore errors when closing an already broken connection
persistent_connection = None
# Get a fresh connection and retry
conn = await get_connection(ctx)
async with conn.cursor(row_factory=psycopg.rows.dict_row) as cur: # pyright: ignore[reportAttributeAccessIssue]
await cur.execute(query, params) # pyright: ignore[reportArgumentType]
if cur.rownumber is None:
return []
else:
return await cur.fetchall()
except Exception as e:
logger.error(f'{ERROR_EXECUTE_QUERY} : {e}')
await ctx.error(f'{ERROR_EXECUTE_QUERY} : {e}')
raise e
def run_async_safe(coro):
"""Windows互換性を考慮した非同期実行関数"""
if platform.system() == 'Windows':
# Windows環境では明示的にSelectorEventLoopを使用
try:
# 既存のループがあるかチェック
loop = asyncio.get_event_loop()
if loop.is_running():
# 既に実行中のループがある場合は新しいタスクとして実行
return loop.create_task(coro)
else:
return loop.run_until_complete(coro)
except RuntimeError:
# ループが存在しない場合は新しく作成
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
try:
return loop.run_until_complete(coro)
finally:
# ループをクリーンアップ
pending = asyncio.all_tasks(loop)
if pending:
loop.run_until_complete(asyncio.gather(*pending, return_exceptions=True))
loop.close()
else:
# Linux/macOSでは通常のasyncio.run()を使用
return asyncio.run(coro)
async def validate_connection():
"""Validate the database connection asynchronously."""
ctx = NoOpCtx()
await execute_query(ctx, None, 'SELECT 1')
def main():
"""Run the MCP server with CLI argument support."""
# Windows互換性を再度確認
setup_windows_compatibility()
parser = argparse.ArgumentParser(
description='An AWS Labs Model Context Protocol (MCP) server for Aurora DSQL'
)
parser.add_argument(
'--cluster_endpoint', required=True, help='Endpoint for your Aurora DSQL cluster'
)
parser.add_argument('--database_user', required=True, help='Database username')
parser.add_argument('--region', required=True)
parser.add_argument(
'--allow-writes',
action='store_true',
help='Allow use of tools that may perform write operations such as transact',
)
parser.add_argument(
'--profile',
help='AWS profile to use for credentials',
)
args = parser.parse_args()
global cluster_endpoint
cluster_endpoint = args.cluster_endpoint
global region
region = args.region
global database_user
database_user = args.database_user
global read_only
read_only = not args.allow_writes
global aws_profile
aws_profile = args.profile
logger.info(
'Aurora DSQL MCP init with CLUSTER_ENDPOINT:{}, REGION: {}, DATABASE_USER:{}, ALLOW-WRITES:{}, AWS_PROFILE:{}',
cluster_endpoint,
region,
database_user,
args.allow_writes,
aws_profile or 'default',
)
global dsql_client
session = boto3.Session(profile_name=aws_profile) if aws_profile else boto3.Session()
dsql_client = session.client('dsql', region_name=region)
try:
# Windows互換性を考慮した接続検証
run_async_safe(validate_connection())
except Exception as e:
logger.error(
f'Failed to create and validate db connection to Aurora DSQL. Exit the MCP server. error: {e}'
)
sys.exit(1)
logger.success('Successfully validated connection to Aurora DSQL Cluster')
logger.info('Starting Aurora DSQL MCP server')
mcp.run()
if __name__ == '__main__':
main()次にインストールを行います。
uv pip install -e . --system
uv tool install .これでバイナリが生成されるはずです。
Claude Desktop 用configファイルを修正
次にClaudeDesktopに組み込むためのconfigファイルを修正します。
{
"mcpServers": {
"awslabs.aurora-dsql-mcp-server": {
"command": "uvx",
"args": [
"--from",
"awslabs-aurora-dsql-mcp-server",
"awslabs.aurora-dsql-mcp-server.exe",
"--cluster_endpoint",
"64abugb3r7ftek2dixuw5fuz6i.dsql.ap-northeast-1.on.aws",
"--region",
"ap-northeast-1",
"--database_user",
"admin",
"--allow-writes",
"--profile",
"default"
],
"env": {
"FASTMCP_LOG_LEVEL": "ERROR"
},
"disabled": false,
"autoApprove": []
}
}
}テスト
ではClaudeDesktopを起動してテストします。
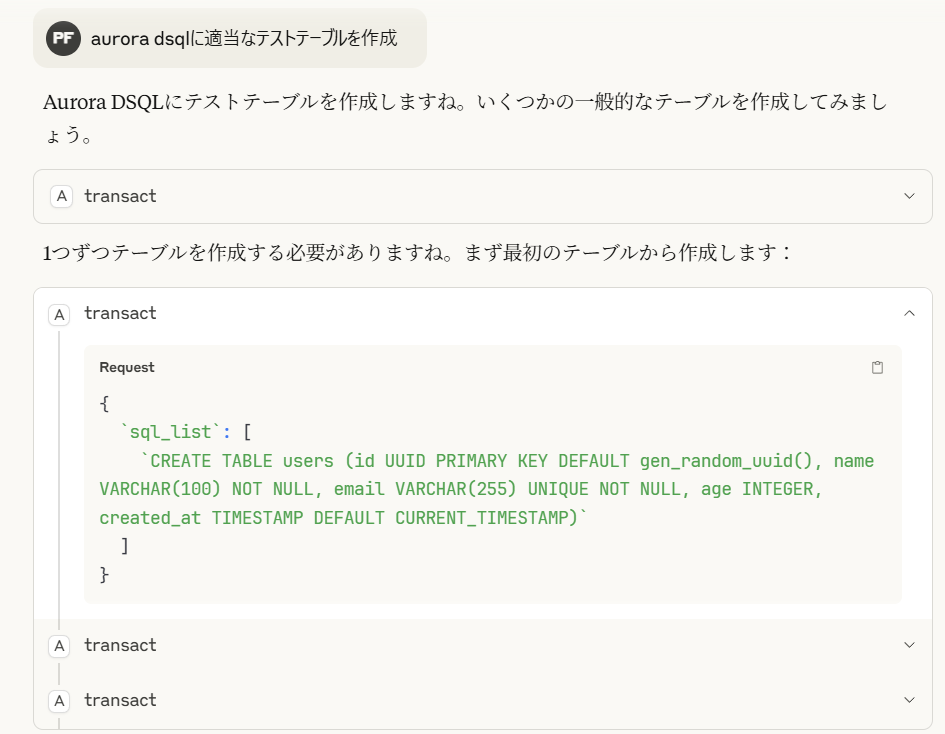

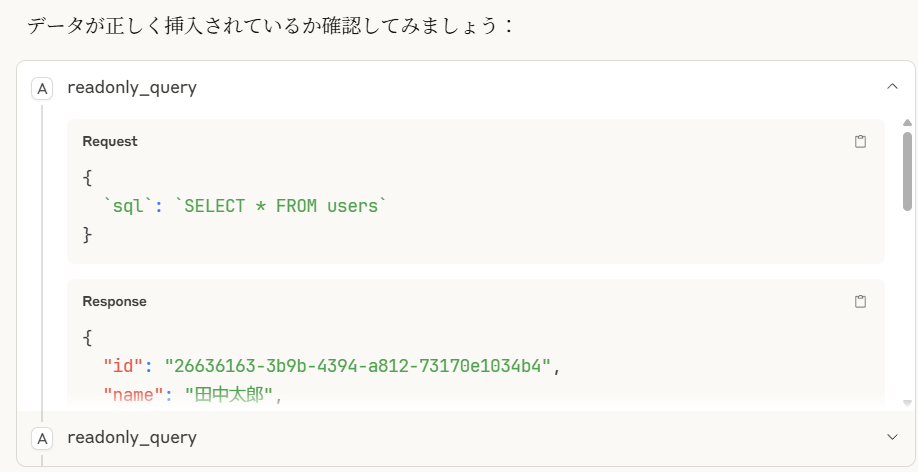
こんな感じで対話型自然言語でデータベースへのテーブル作成やテスト用データの書き込みができています。
--allow-writes オプションに注意
このMCP Serverは--allow-writesを付けて起動しているためDSQLへのデータ書きこみが可能となっています。テスト用には便利ですが、商用環境で用いているDSQL用MCP Serverでこのオプションを使うかは慎重な検討が必要です。
このオプションを付けるとおおよそすべてのデータ操作が可能となってしまいます。指示にSQLを使っていない分意図しないデータ操作が発生する可能性があります。

MCPにセットするIAMポリシーでもデータ操作を許可するかしないかの2択しかなく、MCPサーバの起動オプションでもその2択です。例えばデータのInsertは許可するがDeleteは許可しない、等の制御はserver.pyを書き換える必要があります。このため十分注意した方がよさそうです。