

監視構成の概要
通常は CloudWatch Dashboard で目視監視を行い、予め設定した Alarm の通知が飛ばれたら、詳細の確認と調査を行うような形を想定します。
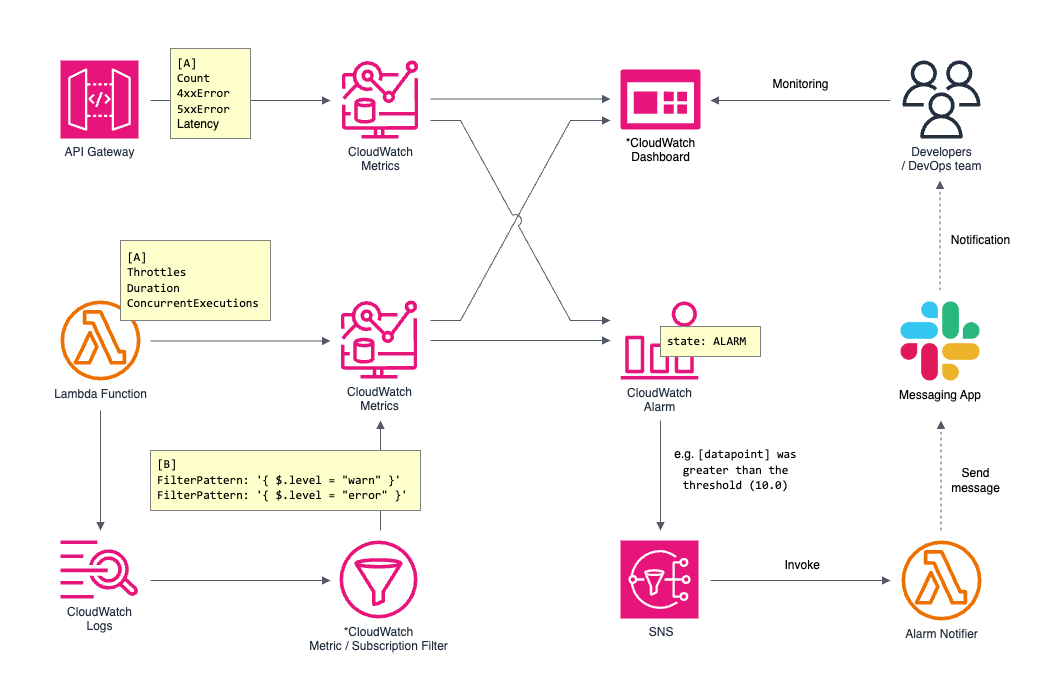
監視対象とする標準メトリクスの例
具体的には、以下のメトリクスを Alarm の対象として閾値を設定し、監視を行うことができます。標準でない監視項目がある場合でも、後述するアプリケーションログを活用して Alarm を設定し、アプリケーション運用ツールとしての使い方をすることもあります。
API Gateway
標準メトリクス | 内容 |
|---|---|
Count |
|
4xxError |
|
5xxError |
|
Lambda
標準メトリクス | 内容 |
|---|---|
Throttles |
|
Duration |
|
ConcurrentExecution |
|
他にも標準メトリクスはたくさんありますので、必要に応じて適宜 CloudWatch から見つけて活用できます。
アプリケーションログ(Lambda)の監視
アプリケーションでは AWS Lambda Powertools ライブラリ等を利用し、以下のような JSON 構造化ログを出力することを基本とします。
{
"cold_start": true,
"function_arn": "arn:aws:lambda:us-east-1:123456789012:function:shopping-cart-api-lambda",
"function_memory_size": 128,
"function_request_id": "c6af9ac6-7b61-11e6-9a41-93e812345678",
"function_name": "shopping-cart-api-lambda",
"level": "ERROR",
"message": "This is an ERROR log with some context",
"service": "shopping-cart-api-handler",
"timestamp": "2023-12-12T21:21:08.921Z",
"xray_trace_id": "abcdef123456abcdef123456abcdef123456"
}このように構造化されているログは、CloudWatch Logs のコンソールから { $.level = "ERROR" } のような形で項目の値を指定して検索をすることができます。監視目的では、 CloudWatch メトリクスに反映する「Metric Filter」を利用します。またこの仕組みを利用し、CloudWatch Logs の Log Stream から、構造化ログの項目をフィルターにかけ、ヒットしたログを他のサービス(S3, Kinesis, Lambda, etc.)に転送する機能「Subscription Filter」を利用することもできます。
基本的には CloudWatch Logs のコンソールから簡単に作成できます。以下は設定の参考として CloudFormation Template のフォーマットで書いたコードになります。
CoreErrorLogMetricFilter:
Type: AWS::Logs::MetricFilter
DependsOn: CoreLogGroup
Properties:
LogGroupName: !Ref CoreLogGroup
FilterPattern: '{ $.level = "ERROR" }'
MetricTransformations:
- MetricValue: 1
MetricNamespace: !Join [ '', [ 'Logs/', !Ref CoreLambdaFunction ]]
MetricName: ErrorsLog Level が ERROR のログが出力された場合、CloudWatch Logs の Metric Filter によってカスタムメトリクスに登録されます。Alarm を設定すれば、例えば 10 分以内にエラーログの件数が一定数を超えた場合に通知が飛ぶような監視機構が作れるようになります。
Alarm を設定して異常検知を自動化する
CloudWatch Alarm は、メトリクスに閾値を設定し、通常時は OK という状態になります。もし一定の時間枠の中でメトリクスの値が閾値を超えたら(または下回った場合等) ALARM という状態に変わります。この状態変更をトリガーとして、変更後の状態とデータポイントが閾値に対してどうなったかのメッセージを、メールまたは SNS に通知することができます。 また、Alarm の状態変化は、OK → ALARM だけでなく、その逆の場合も検知することが可能です。
ALARM は、標準メトリクスに対して、以下のような設定します。
ApiAll5xxAlarm:
Type: AWS::CloudWatch::Alarm
Properties:
AlarmName: prod-webapi-ApiAll5xx-Alarm
AlarmDescription: Total 5xx count of all APIs
AlarmActions:
- !Ref MonitoringTopic
Namespace: AWS/ApiGateway
Dimensions:
- Name: ApiName
Value: prod-webapi
- Name: Stage
Value: prod
EvaluationPeriods: 5 # 5 minutes
MetricName: 5XXError
Period: 60 # 60 seconds
Statistic: Sum
Threshold: 10 # 10 5xx error response within 5 minutes
ComparisonOperator: GreaterThanThreshold標準メトリクスだけでなく、先ほどの構造化ログと Metric Filter を利用したカスタムメトリクスにも適用可能です。
CoreLambdaErrorsAlarm:
Type: AWS::CloudWatch::Alarm
Properties:
AlarmName: prod-webapi-CoreLambdaErrors-Alarm
AlarmDescription: "Log level `ERROR` count in CoreLambdaFunction"
AlarmActions:
- !Ref MonitoringTopic # SNS Topic
Namespace: !Join [ '', [ 'Logs/', !Ref CoreLambdaFunction ]]
EvaluationPeriods: 5 # 5 minutes
MetricName: Errors
Period: 60 # 60 seconds
Statistic: Sum
Threshold: 10 # 10 error logs within 5 minutes
ComparisonOperator: GreaterThanThresholdメッセージングツールとの連携
CloudWatch Alarm によって SNS へ通知が行われ、SNS は Lambda を Invoke し、Lambda のロジックに Slack, Teams, Chatwork などへの転送処理を書いて対応する構成になります。Lambda から直接通知を行う方法以外でも、EventBridge を使って連携させる方法等もあり、適宜やりやすい方を選ぶ形で問題ありません。
ポイントは、主に DevOpsチームが通知の対象になる想定として、分かりやすく通知内容を把握し、迅速に調査に取り掛かれるようにすることが重要です。例えば、 Slack 上で対応内容や情報の共有が素早く確認できる形が望ましいです。
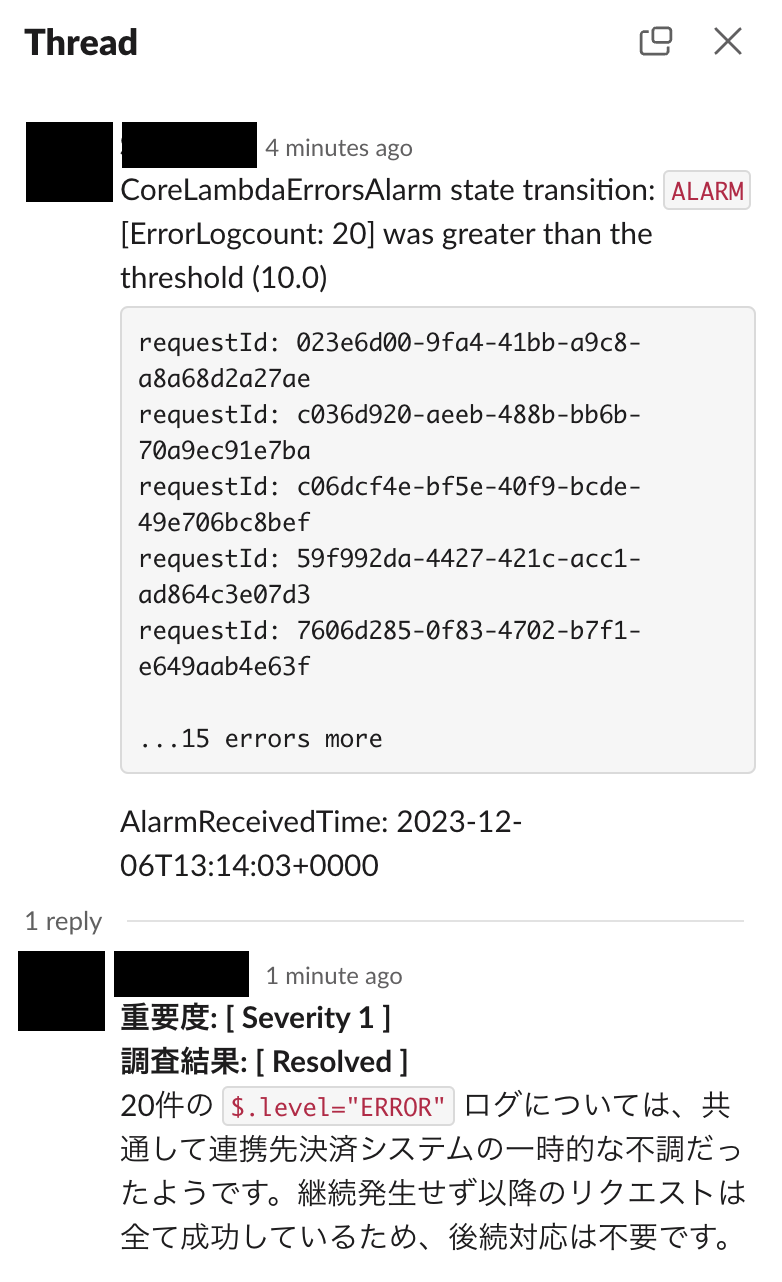
Slack に Alerm のメッセージを送る際、上記のようにカスタマイズを行うことでさらに運用を便利にすることが可能です。SNS メッセージの Payload から Alarm のメトリクス情報を取得し、Metric Filter で利用したのと同じく CloudWatch Logs に { $.level = "ERROR" } という表現で直近のエラーログを取得することが可能です。また、ログを構造化しておくと、該当するログの requestId を取得して、 { $.requestId = “xxx” } のように関連する一連のログのみを検索しやすくなり、調査に役立てます。
このような仕組みを利用して、通知が飛ばれたらすぐにそのスレッドに調査内容やレポート、対応内容等を記録しておくことで、迅速かつ効率よくアプリケーションを運用していくことが可能になります。
この記事に関する内容を含め、AWS環境における監視・モニタリングの仕組み全般において気になる点やサポートが必要な場合は、お気軽にお問い合わせください。