

AWS の各サービスにも SLA(Service Level Agreement)があります。例えは、この記事で説明するAWS IoT Coreの場合、こちらのページ(https://aws.amazon.com/jp/legal/service-level-agreements/)に詳細が記載されています。他にも Amazon CloudFront や AWS Lambda のような主要サービスに関しては、こちらのページ(https://aws.amazon.com/jp/legal/service-level-agreements/)から SLA を確認することは可能です。
また、近年の傾向としては、サービスが全面的に停止するよりも「エラー率の上昇」といった形でサービスの一部分や一部のグループのユーザーに対して影響 が現れる形になってきています。
しかし、AWS でモダンアプリケーション開発を進める際、「とはいえ、AWS のサービスに頼り切ってしまって良いのか。障害時やDR(Disaster Recovery)の観点で、リトライの他に何か取れる策はないのか」という懸念の声を聞くことも多いのではないでしょうか。特に、サーバーレスアーキテクチャを全面的に導入した場合、AWS フルマネージドサービスの稼働状況の影響を強く受けるため、少なくとも DR 観点で考慮が必要な性質の要件やシステムの場合は、この記事で紹介するような構成を検討することが可能です。
障害対応に関する戦略と考え方
モダンアプリケーションやサーバーレス構成の有無に関わらず、基本として考えるべき重要な項目が2点あります。障害発生時を想定して、以下2つに関して明確な目標を持つ必要があります。
- RPO(Recovery Point Objective・目標復旧時点):「どの時点の」データに戻せるか
- RTO(Recovery Time Objective・目標復旧時間)::「いつまでに」システムが復旧できるか
また、高い目標を持てることはもちろん重要ですが、この目標をどう達成するかによってシステムの構成、コスト、対応の方法等も変わってきますので、可能な限り現実的な目標設定が重要です。限りなく100%に近い可用性を担保するために、システム規模やユースケースに見合った形で目標設定と構成を検討することが望ましいです。
その上で、以下の選択肢の中でどれが効果的であるかを考えます。
復旧パターン | RPO・目標復旧時点の目安 | RTO・目標復旧時間の目安 | 構成・適用範囲 | コスト |
|---|---|---|---|---|
①バックアップと復元(Backup & Restore) | 数時間 | 24時間 |
| 低(Low) |
②バイロットライト(Pilot Light) | 数十分 | 数十分 |
| 中(Medium) |
③ウォームスタンバイ(Warm Standby) | 数分 | 数分 |
| 高(High) |
④マルチサイト・アクティブ/アクティブ(Multi-site active/active) | ほぼゼロに近い | ほぼゼロに近い |
| より高い(Higher) |
考え方のポイントとしては、この RPO と RTO の目標をどのあたりに指定するかです。いずれのパタンでも一長一短がありますので悩ましい選択にはなるかと思います。
一方で、この記事では「AWS フルマネージドサービス」にフォーカスをおいて考えてみます。上記のパターンは基本的な観点でのお話になりますので、スケールや障害対応が自動化された AWS フルマネージドサービスにそのまま適用できない部分も存在します。にもかかわらず、復旧パターンを紹介した理由は、どのレベルまで障害対応をすべきか、またどのような根拠でその判断を行うかという観点で良いフレームワークになりますので、ぜひ抑えてみていただければと思います。
「AWS フルマネージドサービス」は、EC2 など通常のサーバーインスタンスと異なり、複数 AZ 単跨る冗長構成が既に取られており、別途利用側から個別サービスごとの障害復旧戦略を考える必要はありません。ですが、そういったサービスは AWS リージョン単位で提供されていることが多いため、「リージョン障害」という単位でシナリオを想定し、どのように対応を行うかについて考えます。
構成の概要
リージョン障害に対応する一つの例として、AWS IoT Core を対象にした構成の例を紹介します。AWS IoT Core はリージョンごとに一つのエンドポイントを持っていて、リージョン障害を想定した場合、AWS IoT Core を入り口として後方に構える各システムコンポーネントの障害対応を考慮するのに良い例になります(※AWS IoT Core ではなく、エンドポイントを持つ他のマネージドサービスに置き換えても良いです)
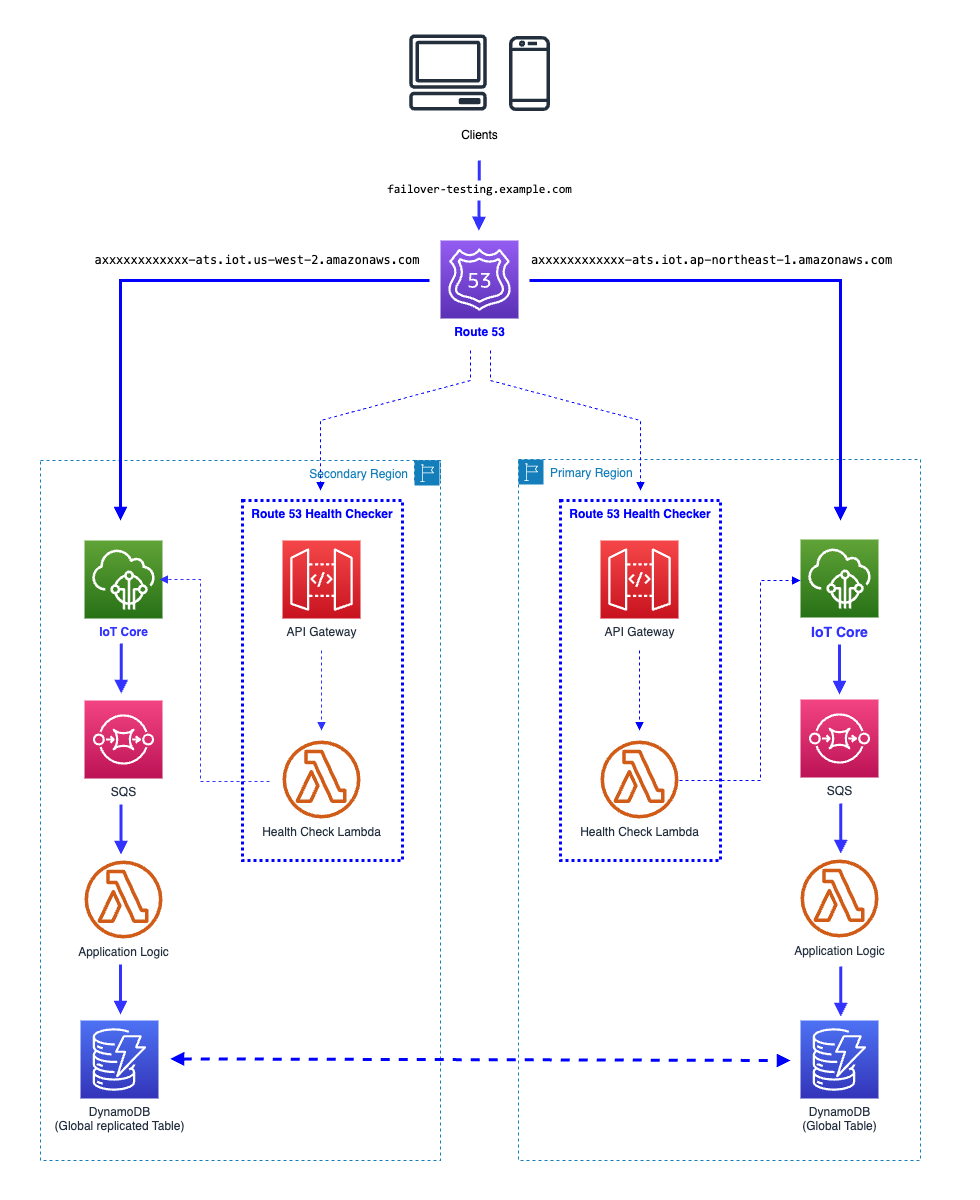
こちらの構成のポイントは、以下になります。
- Amazon DynamoDB Global Tables により、データが複数のリージョンで自動的に同期される
- 全体のシステム構成を複数のリージョンに展開(デプロイ)して、いつでも繋げば動く状態にしておく
- リージョン冗長構成を取りながら固定費用は発生しない(従量課金制のサービスを利用)
- エンドポイントを変えずに、数分でフェイルオーバーすることが可能
構成の詳細
それでは、詳細を見ていきます。構築のポイントは以下3点になります。
① Amazon DynamoDB Global Tables を有効化
Amazon DynamoDB には、DynamoDB Streams の仕組みを活用した Global Tables というリージョン間レプリケーションが可能な機能があります。プライマリリージョンのテーブルにデータが書き込まれたら、自動的にセカンダリリージョンにもデータが書き込まれ、同期されます。これを活用すればマルチリージョン構成でもデータをバックアップ・復元するような作業を行わなう必要がなく、自動フェイルオーバーが可能です。
※ DynamoDB に限らず、Amazon Aurora およびその他のサービスでもフェイルオーバーを実現するための同様の機能はありますが、この記事ではフルマネージドサービスにフォーカスしているため、DynamoDB を例としています。
DynamoDB コンソールを開き、テーブル詳細画面から設定することが可能です。
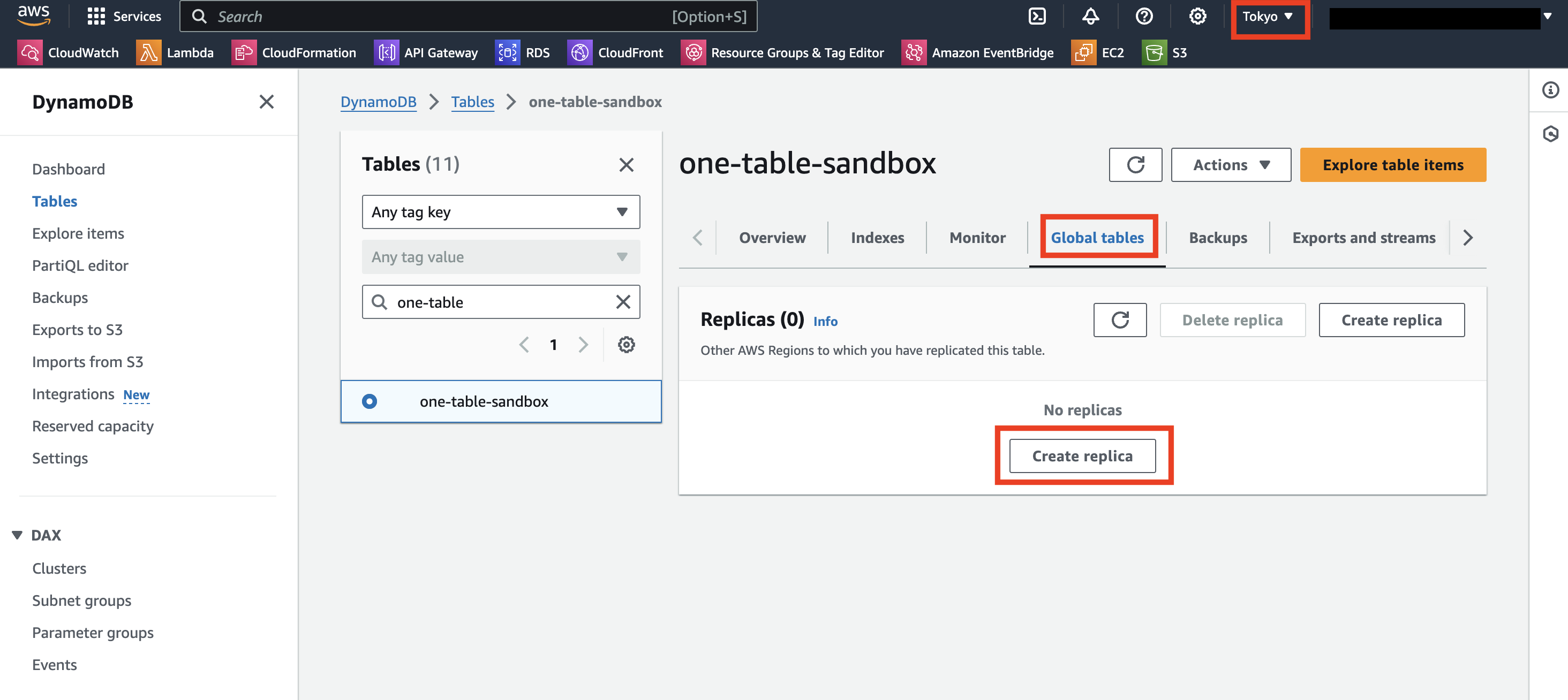
「Create Replica」を押して、セカンダリリージョンとして利用するリージョンを選択します。
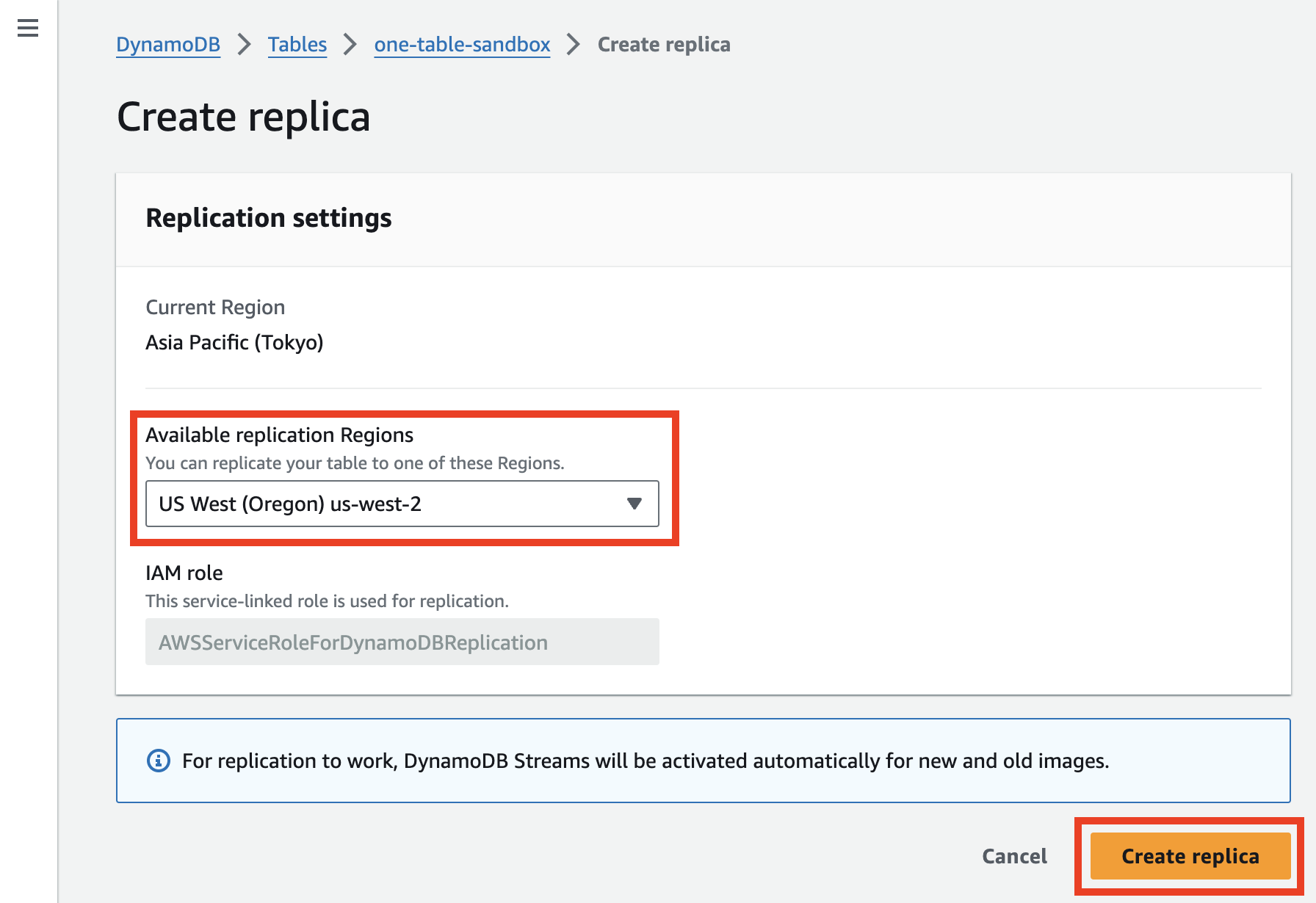
状態が作成中になりますので、数分ほどしばらく待ちます。
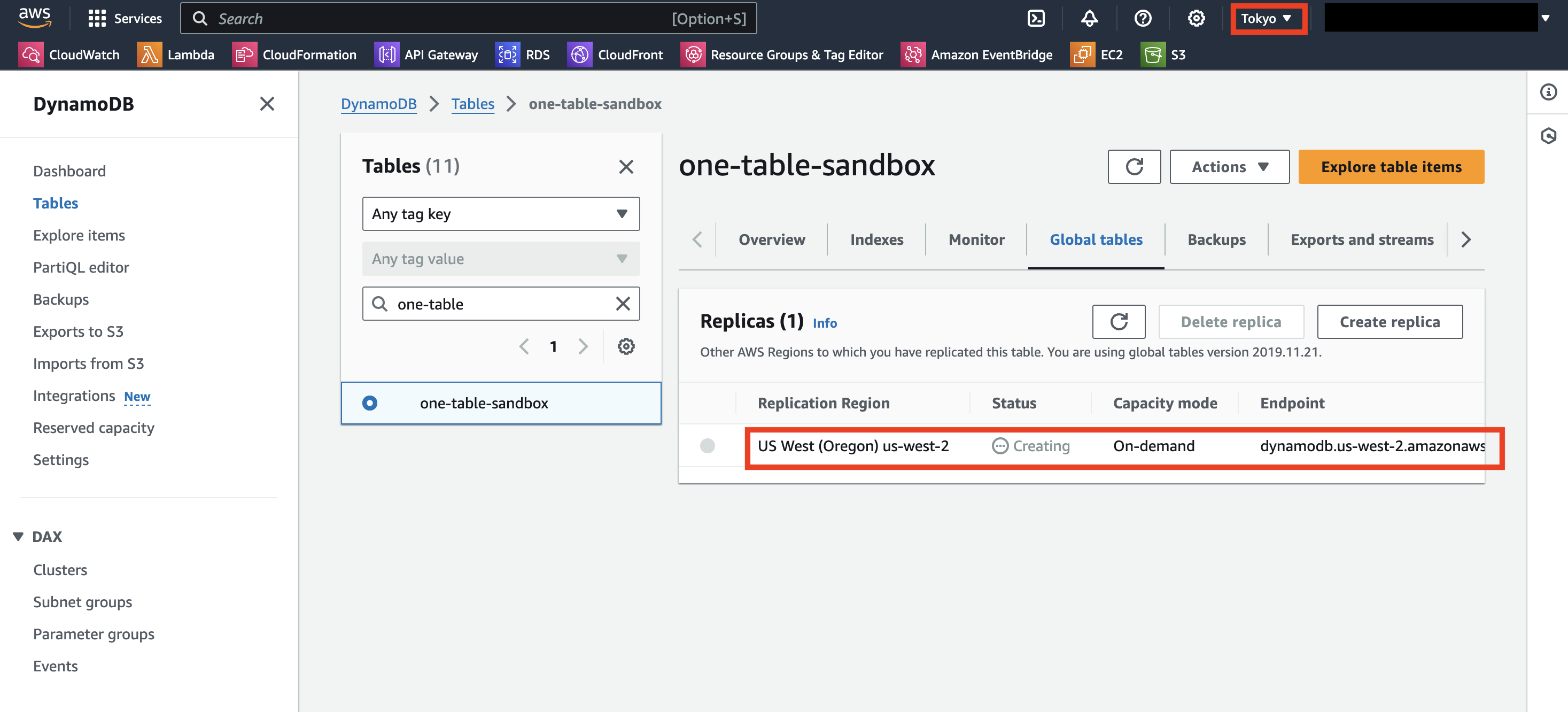
作成が終わったら、レプリケーション先のリージョンで確認してみます。以下のように同じ名前のテーブルが作られ、Global Tables も有効になっています。
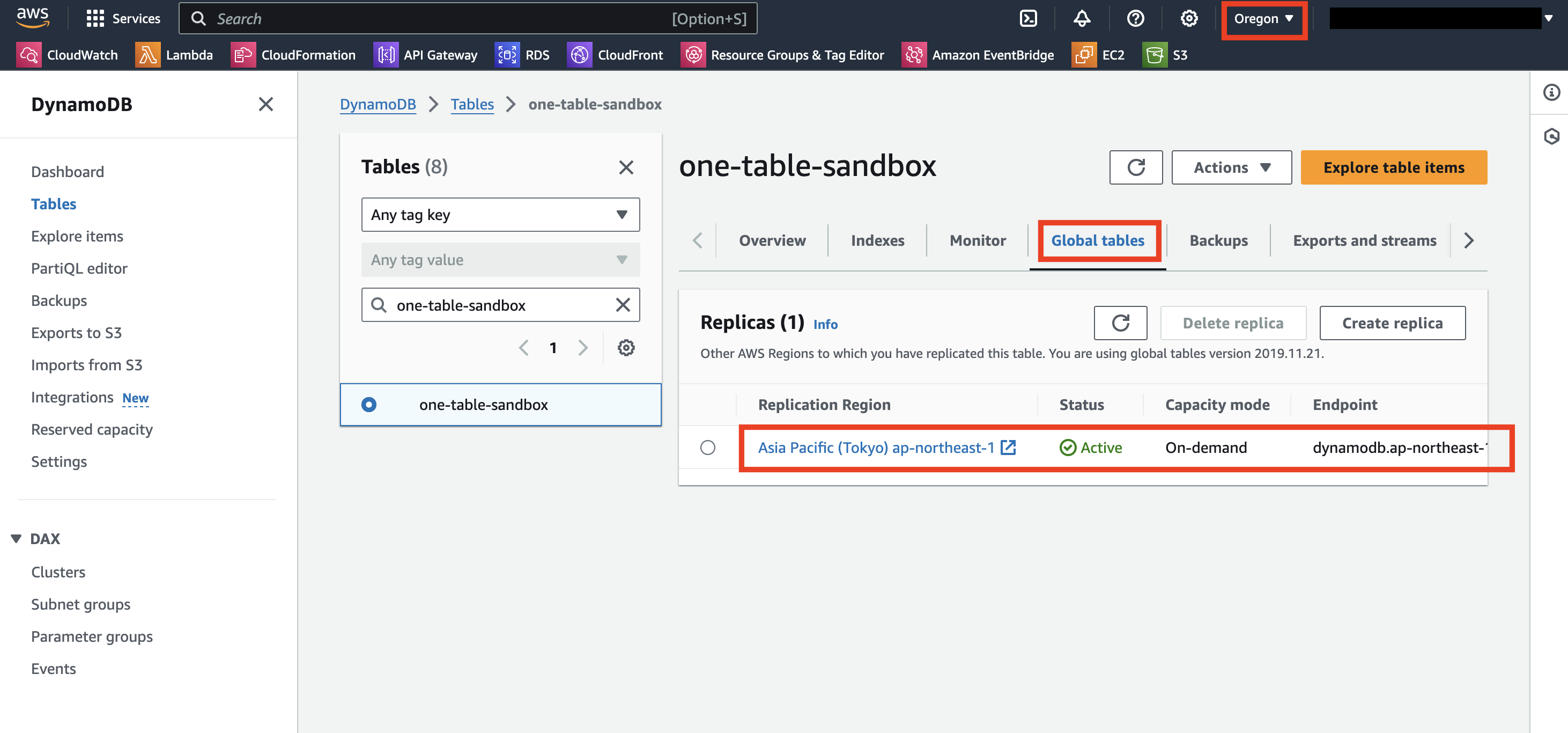
リージョンごとにDynamoDBにアクセスするためのエンドポイントが表示されています。ここは、DynamoDB にアクセスするロジック層(主に AWS Lambda)のリソースのリージョンに合わせて指定するようにすれば、障害時に手動でエンドポイントの向き先を変更する必要がなくまります。
② 複数リージョンへのデプロイ構成
プライマリー、セカンダリリージョンにそれぞれ同じ内容でデプロイしておく必要があります。以下のようなネーミングを検討して、各リージョンごとに DB を除き可能な限りステートレスかつ疎結合な構成にするようにしてください。
基本的には一部手動設定の方が便利な部分などを除き、すべてのAWSリソースは IaC による自動デプロイが必須になります。AWS CDK、AWS CloudFormation、Terraform などを活用してコード化して管理します。
また以下のように、環境名を含める形のネーミングルールを適用します。例えばS3 のバケット名はグローバルでユニークでなければならないため、同じ名前を指定しないように注意が必要です。
{app_name}-{env_name}-{primary/secondary}Route53 Traffic Policy によるファイルオーバーの仕組み
Route53 には、対象エンドポイントへのヘルスチェックと、そのヘルスチェックに失敗した場合プライマリ/セカンダリで向き先の変更を行なってくれる機能があります。この仕組みを利用して、アプリケーションでエンドポイントを変更する作業を行わなくてむ自動フェイルオーバーが可能になります。
まずはヘルスチェックを設定する必要があります。API Gateway + AWS Lambda のシンプルな構成で、マネージドサービスへのアクセスを行い、サービスが落ちていないかをチェックする簡単なコードを作成して Lambda にデプロイしておきます。以下、Lambda のコードの例です。
export const handler = async (event) => {
// マネージドサービスへの呼び出しなど、簡単なアクセスチェック
const response = {
statusCode: 200,
body: JSON.stringify('Hello from Health Check Lambda!'),
}
return response
}Route 53 コンソールを開き、Health Checks を作成します。
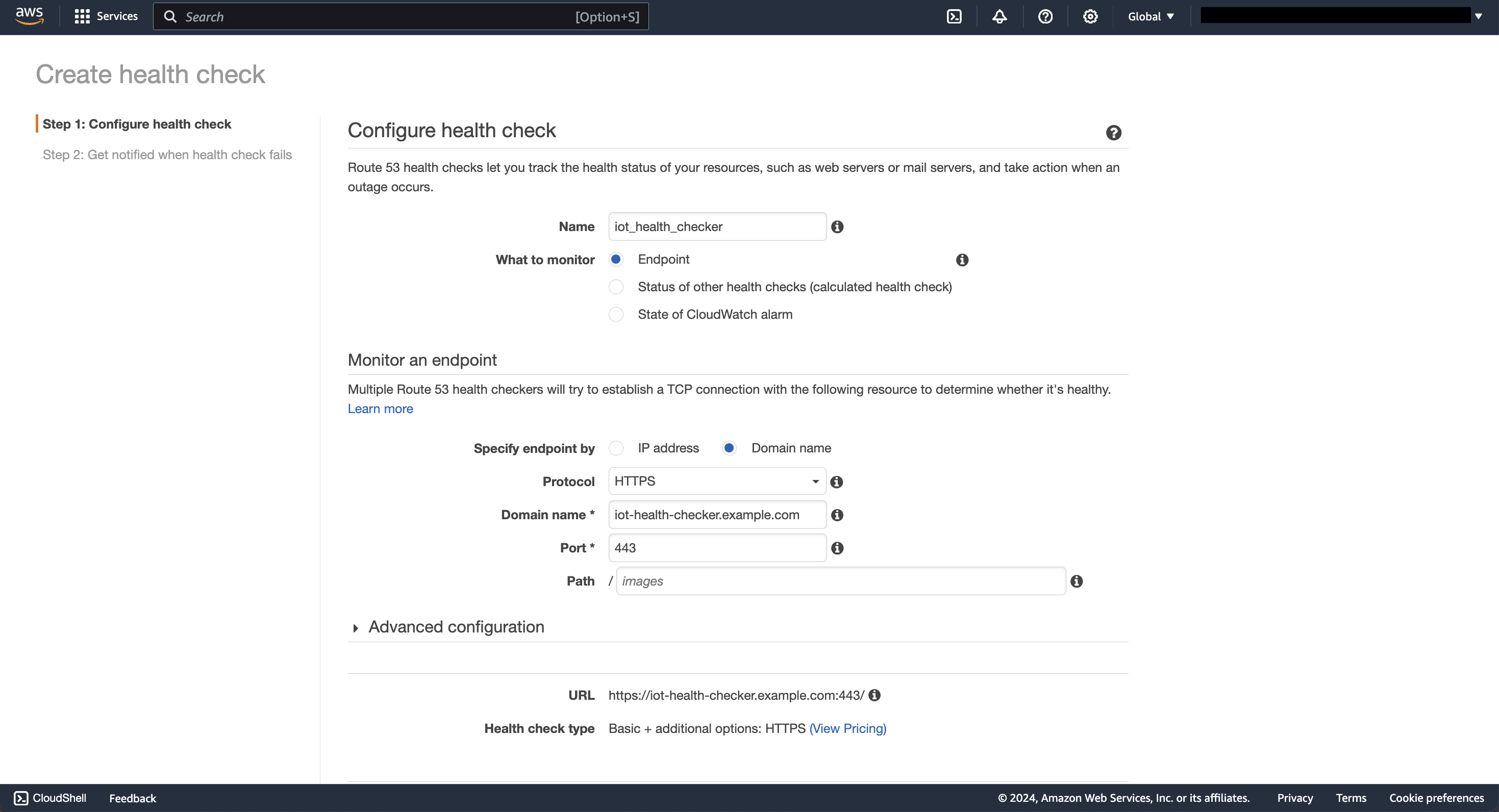
以下のように、先ほど作った API Gateway のエンドポイントを含め設定を行います。
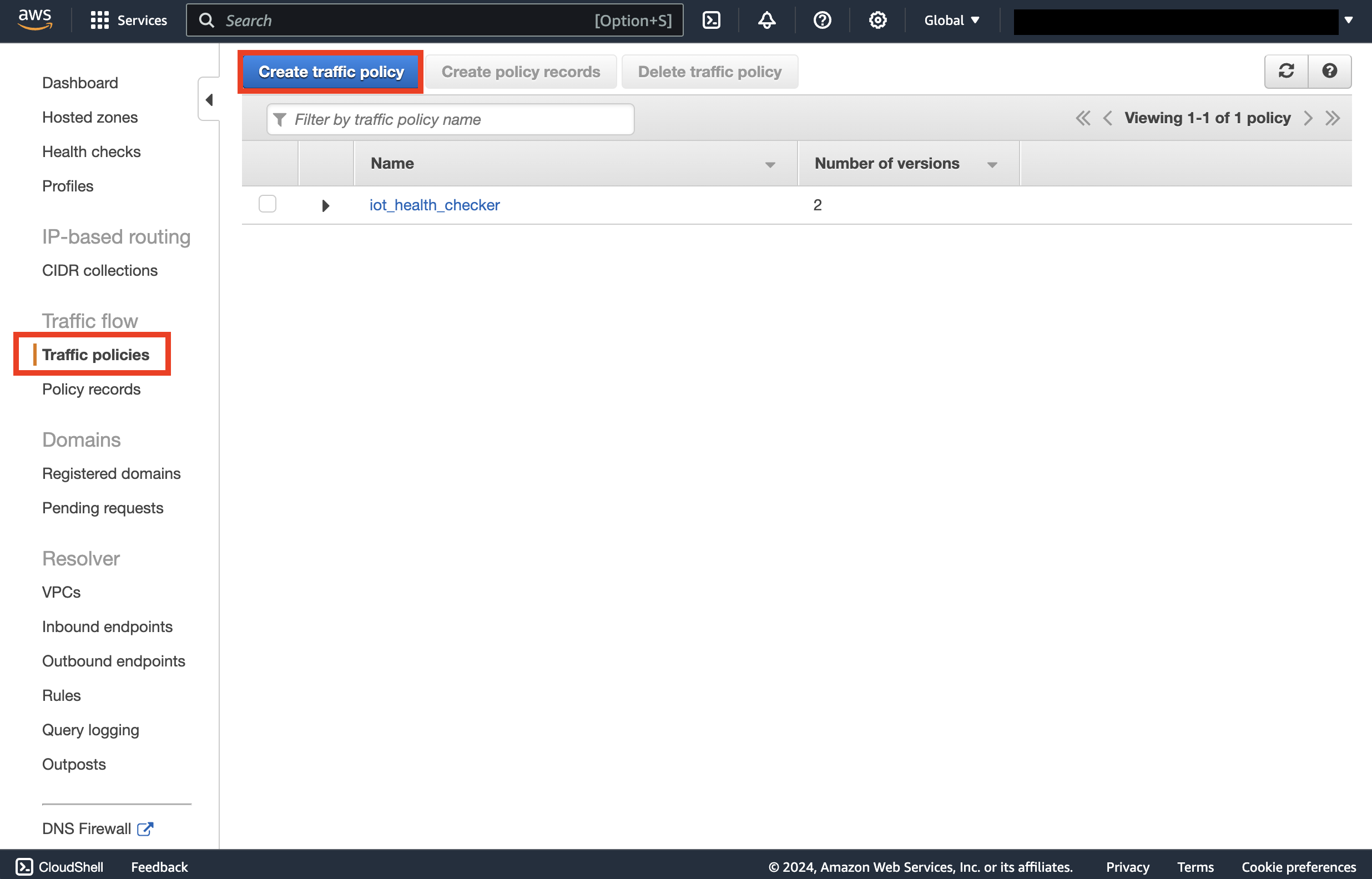
Health Check の作成ができたら、次は Route53 コンソールから Traffic policies を作成します。
Traffic Policy の編集画面を開き、以下のように設定します。フェイルオーバーが起きたら、CNAME に設定した値が書き換わるようになっています。
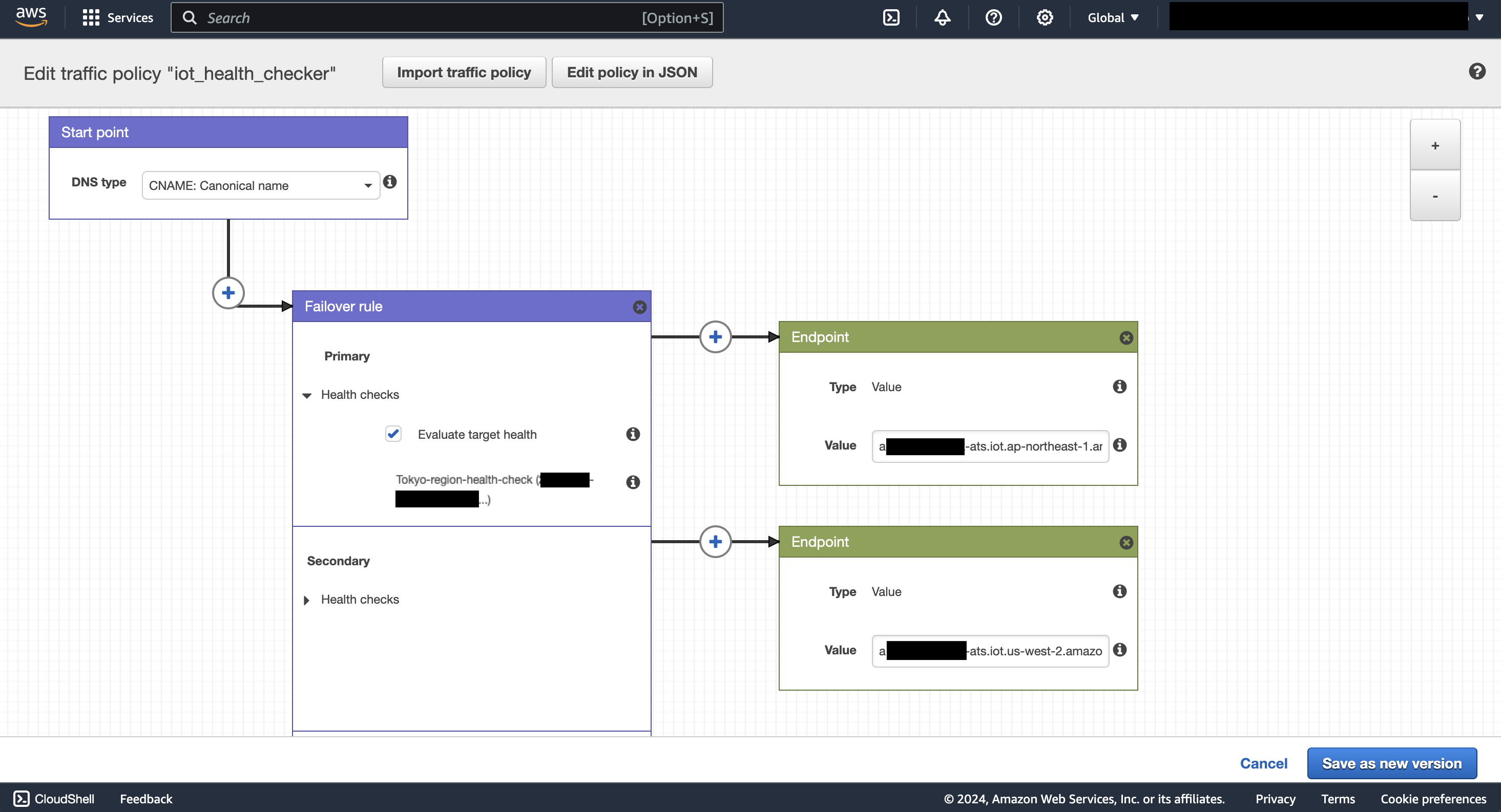
では、まず Hosted Zone から CNAME に共通のエンドポイントを設定し、プライマリーリージョンから試してみます。
$ dig failover-testing.example.com
...
;; ANSWER SECTION:
failover-testing.example.com. 60 IN CNAME axxxxxxxxxxxx-ats.iot.ap-northeast-1.amazonaws.com.ここで、ヘルスチェックの Lambda のコードを以下のように 500 で返すように修正してみます。
export const handler = async (event) => {
const response = {
statusCode: 500,
body: JSON.stringify('Hello from Health Check Lambda!'),
}
return response
}1分ほど経過すると、以下のように CNAME が書き変わっていることが確認できます。
$ dig failover-testing.example.com
...
;; ANSWER SECTION:
failover-testing.example.com. 60 IN CNAME axxxxxxxxxxxx-ats.iot.us-west-2.amazonaws.com.特記事項
AWS IoT Core の場合、Thing や証明書などリージョンごとに管理されるリソースがあります。このようなものに関してはプライマリーリージョンへの登録時に、セカンダリーリージョンにも同じ内容で同期をとるような仕組みの作り込みが多少必要になります。これに関して、AWS 公式ブログでは Step Functions を利用した同期の仕組みが紹介されています。
また、このような DNS フェイルオーバーの仕組みは AWS IoT Core だけでなく他のサービスでの適用が可能です。
参考資料
本記事については、以下の資料を元にしています。詳細が気になる方は、是非合わせてチェックしてみてください。
- (AWS公式ドキュメント)クラウド内での災害対策オプション
- (AWS公式ドキュメント)DR 戦略の定義
- (AWS公式ブログ)How to implement a disaster recovery solution for IoT platforms on AWS
- (AWS公式ブログ)事業継続性が求められる基幹システムの DR 戦略
この記事に関する内容を含め、AWSのシステム構成全般において気になる点やサポートが必要な場合は、お気軽にお問い合わせください。